python2饱受诟病的问题就是字符编码的问题,但是现在很多包还是使用python2…
本文总结python2字符编码的问题。总的一个原则:在python内部,将字符串都转化为unicode。
文件,或者终端输入的字符串可能是GBK,UTF8等各种格式。所以,正常情况下,我们需要将代码中的字符串,终端的字符格式进行设置。在处理文本文件的时候,也需要知道文本文件的字符编码。
字符编码转化与默认编码
在python中, 字符编码使用encode,decode两个函数。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312’),表示将gb2312编码的字符串str1转换成unicode编码。解码成unicode也可以使用str = unicode(str, ‘utf-8’), 但是连续使用str = unicode(str, ‘utf-8’) 会出错,而连续使用str = str.decode(‘utf-8’) 没问题
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode(‘gb2312’),表示将unicode编码的字符串str2转换成gb2312编码。
修改默认编码:
修改ubuntu python默认编码为utf-8: 在/usr/lib/python2.7/sitecustomize.py添加:
mac中的路径为:/usr/local/lib/python2.7/site-packages/sitecustomize.py
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
py文件头设置
#! /usr/bin/env python2.7
#coding=utf-8
utf-8 和unicode
先看一张图,很清除表示python的编码问题。
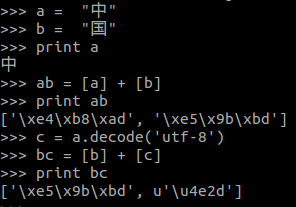
- 使用decode将utf8转换为unicode
- 使用list来保存字符的时候,除非是英文或者字符串,其他字符, 例如“中”, 都会被转化为 ‘\xe4\xb8\xad‘这样的形式。(不要慌)。 如果想知道一个字符在内存中的表示,可以通过把它防盗list中,再打印出来的方法。
- 这个中文”中“在内存中占三字节, 而转化为unicode之后为两字节 u‘\u4e2d’ 转化为unicode之后,中英文都是两个字节。这样提供给我们统一的大小,从而可以对字符串进行遍历。
- 从print bc中,可以从b和c分别是utf8, unicode编码
- 上面的前提是输入的字符是utf8. 我们通过将系统的python默认字符编码来设置这个值(下文)。 写在代码中的字符串编码通过文件头的编码来指定。设置了以上默认编码之后,无论是从文件或者代码中读来的字符串都是utf8格式,一般都需要统一转换为unicode进行处理。像jieba这种工具包,不转换也可以,那是因为jieba代码内部在获取输入之后进行字符转换decode。在返回结果的时候又encode在default_encoding. 所以让人感觉不到字符编码的存在。
unicode和utf-8的关系
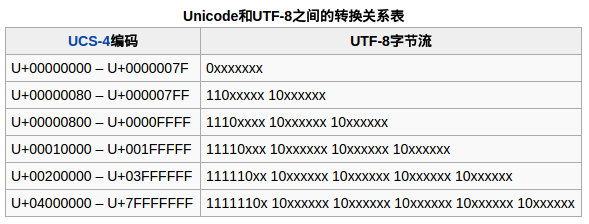
unicode是等长编码,所有字节都是两个字节。而utf8是变长编码(见上图, 来自wikipedia)。从第一字节几个1开头可以判断该utf8字符占多少字节。将utf8字符提取出来的方法通常是先判断该字符长度,再把该部分的字节提取出来,再调用函数取得对应的字符形式。
python中utf-8与unicode单个字符转换
在python中,已知字节表示获取字符表示的库函数是chr和unichr。 反方向,要知道一个字符的字节表示的库函数是ord。任何一个字符多个字节可以组成一个数字。这个数字也可以认为是序号。 例如‘d’的序号是100, ‘中’的序号是20013. 如图
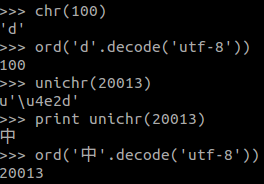
ps: 在lua中对应的函数是string.byte, string.char
理解
如果没有python帮我们实现utf8到unicode的编码转化,我们需要手动实现,需要根据每个字节以几个1开头判断该字符占几字节。
转化为unicode之后,就可以对字符串进行遍历。如下图:

试问:如上图的第一行,你怎么知道第几个字是什么呢?而转化为unicode的意义也就在这里。