1 hts, hts_engine合成
hts, hts_engine环境配置不谈。这里只提怎么用。
1.1 hts训练
/configure MGCORDER=12 MGCLSP=1 GAMMA=1 FREQWARP=0.0 LNGAIN=0 NSTATE=7 NITER=10 WFLOOR=5 \
--with-tcl-search-path=/home/sooda/speech/marytts/lib/external/bin \
--with-fest-search-path=/home/sooda/speech/festival_all/festival/examples \
--with-sptk-search-path=/home/sooda/speech/marytts/lib/external/bin \
--with-hts-search-path=/home/sooda/speech/marytts/lib/external/bin \
--with-hts-engine-search-path=/home/sooda/speech/marytts/lib/external/bin
各工具包的路径可能需要更改。各配置参数可修改。然后直接make就可以完成训练。使用以上命令可以用于测试官网官网例子。
这些例子都是直接lab到声音的训练,没有给出lab的提取。这部分可以参考marytts。
hts训练的模型文件为:
1.2 hts_engine合成
从lab生成raw文件:
/home/sooda/speech/marytts/lib/external/bin/hts_engine -td tree-dur.inf -tf tree-lf0.inf -tm tree-mgc.inf -tl tree-lpf.inf -md dur.pdf -mf lf0.pdf -mm mgc.pdf -ml lpf.pdf -dm mgc.win1 -dm mgc.win2 -dm mgc.win3 -df lf0.win1 -df lf0.win2 -df lf0.win3 -dl lpf.win1 -s 44100 -p 221 -a 0.53 -g 0 -l -b 0.4 -cm gv-mgc.pdf -cf gv-lf0.pdf -k gv-switch.inf -em tree-gv-mgc.inf -ef tree-gv-lf0.inf -b 0.0 -or rawName labName
从raw到wav:
/usr/bin/sox -c 1 -s -2 -t raw -r 44100 rawName -c 1 -s -2 -t wav -r 44100 wavName
可能会有sox警告, 解决警告的合成命令为:
/usr/bin/sox -c 1 -e signed-integer -b 16 -t raw -r 44100 rawName -c 1 -e signed-integer -b 16 -t wav -r 44100 wavName
新版本的hts 2.3 alpha 和hts engine 1.07以后,支持将模型文件整合成一个htsvoice文件。合成命令为:
/home/research/tools/hts23/bin/hts_engine -m voiceName.htsvoice -ow wavName labName
2 marytts训练
2.1 marytts模型文件和hts_engine的不同
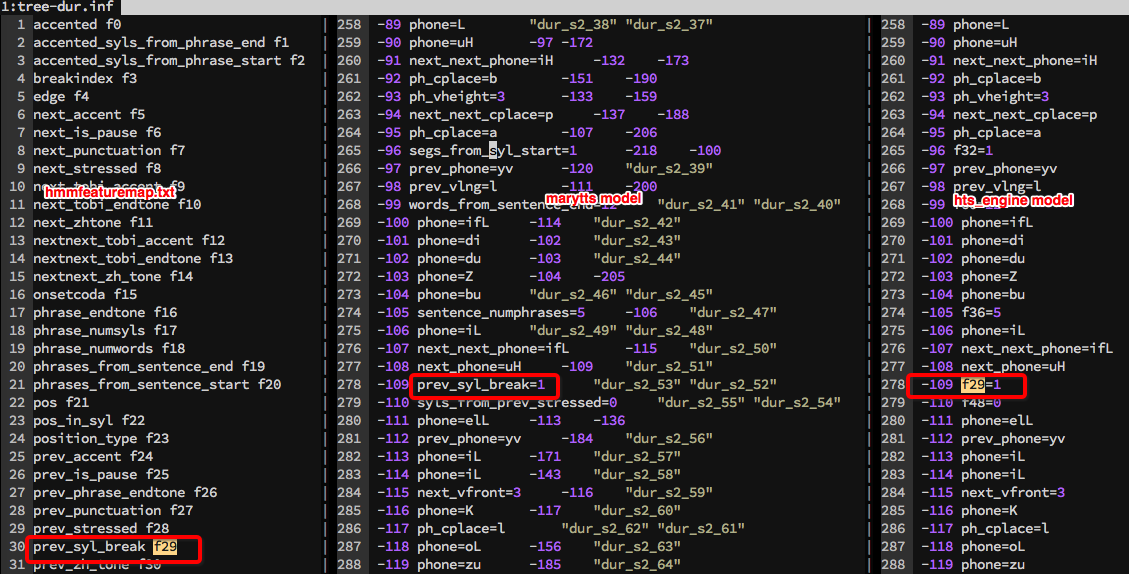
marytts使用hts2.2和hts_engine1.05。 marytts在hts训练核心部分并没有做什么工作。但是marytts在合成部分增加了mix excitation, 使得合成效果更加自然。 marytts为了实现mix excitation,提取了str-mary, mag-mary等特征,与hts自带脚本不同。提取声学特征的代码写在hts/data/Makefile里面。如图:

除了mix excitation的不同,marytts在将训练完成的模型文件打包的时候,对模型做了更改。把特征编号转化为特征名字。所以如果直接将走完整个训练流程并打包发布后, 想要用hts/voices/路径下的模型测试hts_engine合成效果是行不通的。正确的做法是,在打包之前将hts/voices模型备份,避免更改。
2.2 hts adapt训练
术语: adaptSpeaker表示训练数据较少者。adaptTrainSpeaker表示拥有大量数据者。
数据准备: phonelab, phonefeatures,ts/data/raw都要有trainer和adapter的。数据放置到对应路径。重命名,大量dirty work
配置问题: 直接看图。

- 建议speaker名称用相同字母数表示,否则speakmask会出错。
- adaptf0range有顺序问题。
- adapthead用于删选用于adapt的文件起始名称
- 有多个步骤需要设置adaptScript为true
这样配置之后还有错误的话,估计就是某个声学特征提取的问题。 直接到hts/data/下查看。
2.3 marytts模型打包文件
marytts通过读取voice.config来读取对应的文件。这里少了一些win文件,应该是被写在代码中了。

在 marytts-runtime/src/main/java/marytts/htsengine/HMMData.java的initHMMData加载模型数据
3 marytts合成流程
3.1 总体流程
特征的提取,请参考之前的文章:marytts训练流程。 这里主要讲如何将一个lab文件转化为声音。涉及的模块主要有:acousticModel, systhesiser, signalproc等。
从1.2节,我们可以看到在hts_engine中,声音的合成是直接通过调用hts_engine的api合成。这样就失去了对合成过程的控制。
marytts的合成算法本质上也是hts_engine的算法(加入mix excitation扩展)。 marytts通过各个部分的分别合成,使得合成更加灵活。marytts合成分解如下:
- [可选] 在acousticModel部分, 合成f0和duration。 如果需要某些prosody效果,直接在f0和duration中修改。
- 在systhesis部分, 合成str, mgc等其他参数。如果f0,duration已经合成,则不再合成。
- 调用vocoder将str, mgc, f0等参数合成声音。 如果所需要的效果器是调整语速这种则在这里对hmm模型直接修改。
- [可选] 如果需要特殊的音效,调用effecApply对已经合成的声音进行修正。涉及信号处理signalproc。 注意:调整f0,duration不在这个步骤
以下是源码笔记,讲解合成细节。具体内容会根据理解变更。
3.2 acousticModel预测f0,duration细节
一些知识:
- HMMModel中的成员变量 uttModel = Map<List
, HTSUttModel>> 保存特征和句子模型的一个映射。 - 在predictAndSetDuration中预测每个状态的持续时间
- predictAndSetF0预测每帧的f0值
- targets, predictTargets就是音素序列。每个target对应一个音素。
predictAndSetDuration流程:
- 对于每个target,预测其duration(每个状态的duration和总的duration)
- 再对每个状态对应多少帧,设置是否voiced等
- 再设置maryxml上的“d”属性。若该属性已经存在,则累加该值
- 各个状态的持续时间保存在htsUttModel中。可以为后面的合成所用。

predictAndSetF0流程:
- 调用
hasMaximumlikelihoodParameterGeneration(um, hmmVoicedModel)来预测f0参数。这里载入的hmmVoicedModel只是f0的model,所以只合成f0参数。在后面的hts_engine合成里面,如果f0,duration已经合成,则只合成str, mgc - 生成maryxml的f0属性值
- boundary model: 碰到boundary, 若未设置duration值,则统一设置为400
通过predictAndSetDuration, predictAndSetF0之后,可以应用prosody标签的变化,对声调进行修正。
3.3 合成声音
调用关系图:

关键代码:
Synthesis:synthesizeOneSection
EffectsApplier ef = new EffectsApplier();
//如果效果器是hmm类型的(duration,f0等),则直接修改模型
ef.setHMMEffectParameters(voice, currentEffect); //解析字符串,实例化效果器
AudioInputStream ais = null;
ais = voice.synthesize(tokensAndBoundaries, outputParams);
//应用效果器, f0, duration已经直接在hmm模型修改了。
//效果器代码在mary-runtime.signalproc.effects里面
if (currentEffect != null && !currentEffect.equals("")) {
ais = ef.apply(ais, currentEffect);
}
HTSEngine:process
HTSParameterGeneration pdf2par = new HTSParameterGeneration();
//生成声学参数
pdf2par.htsMaximumLikelihoodParameterGeneration(um, hmmv.getHMMData());
HTSVocoder par2speech = new HTSVocoder();
//调用vocoder生成声音
AudioInputStream ais = par2speech.htsMLSAVocoder(pdf2par, hmmv.getHMMData());
if (tokensAndBoundaries != null)
setRealisedProsody(tokensAndBoundaries, um);