本文要点
- CT压缩原理
- 目标跟踪框架:采样,bayes分类器训练,更新
随机观测矩阵
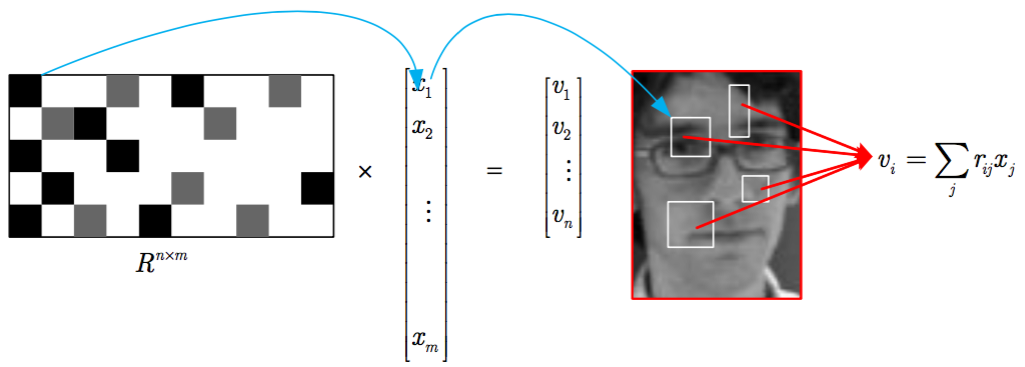
上图中R是投影矩阵,x是haar特征。 为了处理scale的问题,haar特征遍历当前图片的所有矩形。一个矩形框由其左上角点和右下角点决定,左上角,右下角可能位置均为wh,则矩形总数为(wh)(wh)。对于w=h=30的图片,其特征总数m=10^6.如果提取所有的特征再计算相似度,那么效率会很低。
上面的R的稀疏矩阵,其取值为:

理论证明,在s=2,3时候,压缩后信息不会丢失(详见论文2.2)。这样可以节省2/3的计算量。本文更进一步,s=m/4。这样每行的只有2-4个非0值。只需要计算和存储这部分数据即可。从上图中看,R矩阵中,黑色代表1,灰色表示-1,白色这样计算次数最多为O(4n).若降维为n=50维,那么只需要200次乘法.这就是CT压缩提高效率的秘密。而且,很重要的一点,这是边采集边压缩,与通常使用的先采集再压缩不同,可以节省大量的空间,计算,传输资源。
整体流程

在a中,对于当前人脸的位置,较近位置采集正样本,远离位置采集负样本。 然后通过滤波器获取特征值。这里通过不同的卷积核获取特征值,因为特征值数目较多(10的6次方级),需要降维(压缩感知的作用,降到50维)。将特征降维后,使用朴素贝叶斯进行分类。
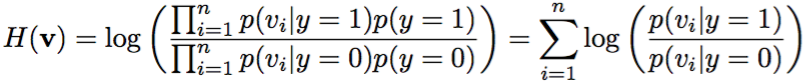
这个降维后的每个维的值可以看作一个高斯模型来建模(有理论依据)。
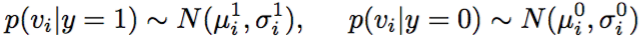
在b中,对于新帧,使用当前高斯模型获取概率,将概率相乘得到置信度,最大的则认为是目标位置。同时用这个位置更新高斯模型。
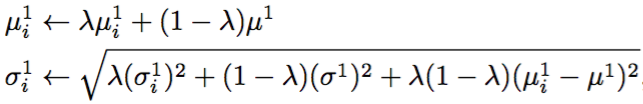
伪代码:

代码细节
压缩感知权重,滤波器组位置
vector<vector<Rect> > features; //ct 特征相对与当前rect的偏移位置,及其长宽。每个降维特征有多个rect
vector<vector<float> > featuresWeight; //特征权重
for (int i=0; i<_numFeature; i++)
{
numRect = cvFloor(rng.uniform((double)featureMinNumRect, (double)featureMaxNumRect));
for (int j=0; j<numRect; j++)
{
rectTemp.x = cvFloor(rng.uniform(0.0, (double)(_objectBox.width - 3)));
rectTemp.y = cvFloor(rng.uniform(0.0, (double)(_objectBox.height - 3)));
rectTemp.width = cvCeil(rng.uniform(0.0, (double)(_objectBox.width - rectTemp.x - 2)));
rectTemp.height = cvCeil(rng.uniform(0.0, (double)(_objectBox.height - rectTemp.y - 2)));
features[i].push_back(rectTemp);
weightTemp = (float)pow(-1.0, cvFloor(rng.uniform(0.0, 2.0))) / sqrt(float(numRect));
featuresWeight[i].push_back(weightTemp);
}
}
降维
for (int i=0; i<featureNum; i++)
{
for (int j=0; j<sampleBoxSize; j++)
{
tempValue = 0.0f;
for (size_t k=0; k<features[i].size(); k++)
{
xMin = _sampleBox[j].x + features[i][k].x;
xMax = _sampleBox[j].x + features[i][k].x + features[i][k].width;
yMin = _sampleBox[j].y + features[i][k].y;
yMax = _sampleBox[j].y + features[i][k].y + features[i][k].height;
tempValue += featuresWeight[i][k] * //使用积分图快速计算卷积
(_imageIntegral.at<float>(yMin, xMin) +
_imageIntegral.at<float>(yMax, xMax) -
_imageIntegral.at<float>(yMin, xMax) -
_imageIntegral.at<float>(yMax, xMin));
}
_sampleFeatureValue.at<float>(i,j) = tempValue;
}
}
更新高斯模型
for (int i=0; i<featureNum; i++)
{
meanStdDev(_sampleFeatureValue.row(i), muTemp, sigmaTemp);
_sigma[i] = (float)sqrt( _learnRate*_sigma[i]*_sigma[i]
+ (1.0f-_learnRate)*sigmaTemp.val[0]*sigmaTemp.val[0]
+ _learnRate*(1.0f-_learnRate)
*(_mu[i]-muTemp.val[0])*(_mu[i]-muTemp.val[0])); // equation 6 in paper
_mu[i] = _mu[i]*_learnRate + (1.0f-_learnRate)*muTemp.val[0]; // equation 6 in paper
}
最大似然估计
for (int j=0; j<sampleBoxNum; j++)
{
sumRadio = 0.0f;
for (int i=0; i<featureNum; i++)
{
pPos = exp( (_sampleFeatureValue.at<float>(i,j)-_muPos[i])
*(_sampleFeatureValue.at<float>(i,j)-_muPos[i])
/ -(2.0f*_sigmaPos[i]*_sigmaPos[i]+1e-30) ) / (_sigmaPos[i]+1e-30);
pNeg = exp( (_sampleFeatureValue.at<float>(i,j)-_muNeg[i])
*(_sampleFeatureValue.at<float>(i,j)-_muNeg[i])
/ -(2.0f*_sigmaNeg[i]*_sigmaNeg[i]+1e-30) ) / (_sigmaNeg[i]+1e-30);
sumRadio += log(pPos+1e-30) - log(pNeg+1e-30);// equation 4
}
if (_radioMax < sumRadio)
{
_radioMax = sumRadio;
_radioMaxIndex = j;
}
}
总结
- 本文基于压缩感知的方法,大大提高了压缩效率。
- 用简练的代码,展示了pn学习,在线跟踪,朴素贝叶斯的使用。
- 跟踪效果不错,这种方法缺点很明显,并没有考虑目标尺度的变化,使用相同大小的boundingBox。肯定是有问题的。