Convolutional Neural Networks for Sentence Classification
本文发表在emnlp2014上,目前引入158次。将cnn用在自然语言处理,在情感分析等任务中取得不错的结果,本文的处理流程,已经成为深度学习文本分析的基本流程。
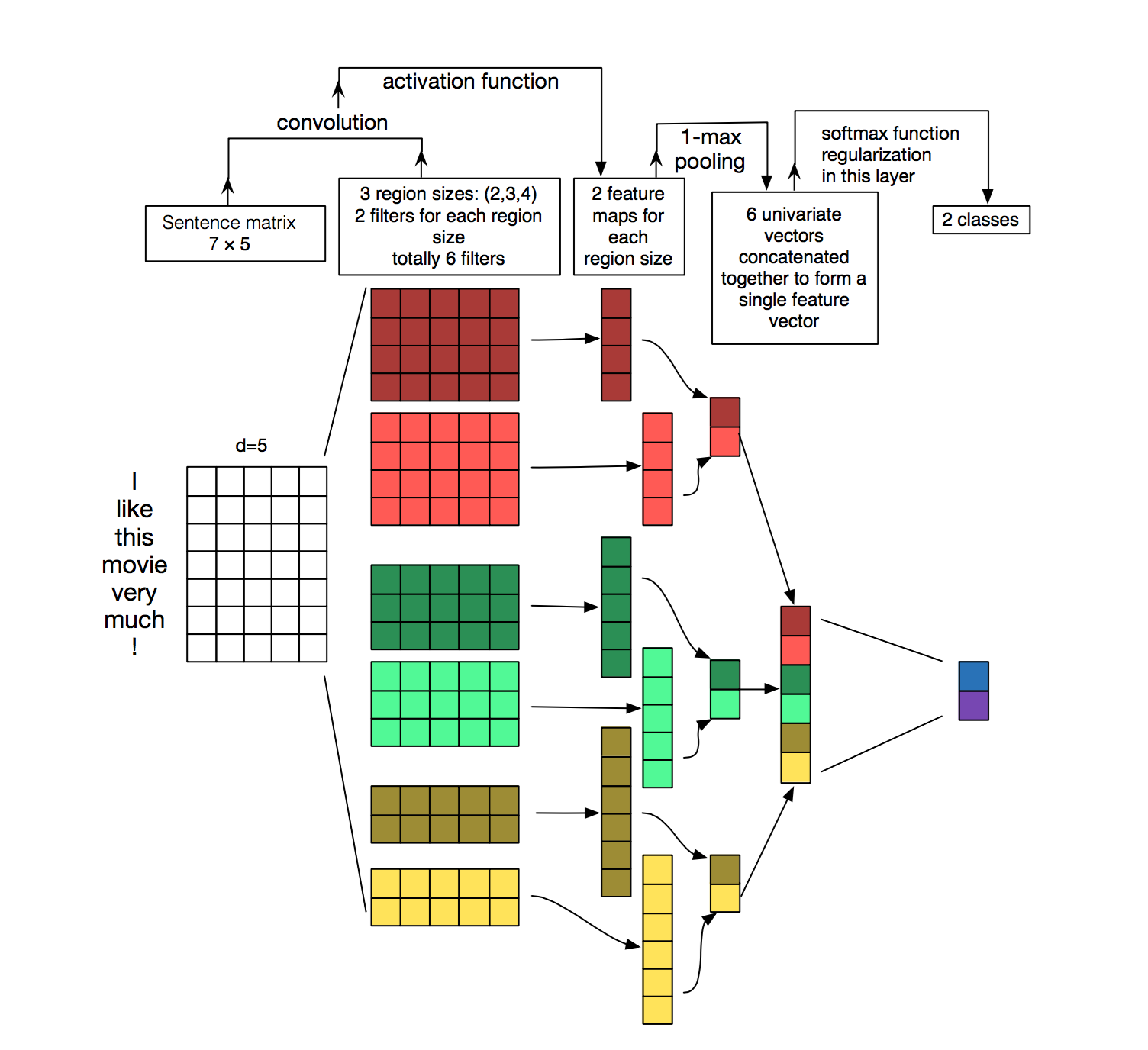
处理流程

最左边是句子基于词向量的表示(词向量:将每个字表示为相同维度的向量,而且向量之间的距离可以用来表达词意距离)。词向量可以直接选取word2vec训练结果,也可以先直接随机初始化,再在学习的过程中不断优化。本文用到两个通道,每个通道是一种词向量表示。其中一个通道保持不变,另外一个通道则接受bp的调整。
这里的卷积和图片的卷积略有不同,一般采用narrow convolution。也就是,卷积核的宽度采用与词向量相同的宽度。这样,每个句子的卷积结果为:1 x (sentence_length - filter_size + 1 )
通过max_pooling将这个不同sentence_length - filter_size + 1维的数据降为1维。再把所有卷积核的结果连成长向量,放入全连接层,使用softmax进行分类任务。
从下图可以更清楚看出这个流程。需要注意的是,卷积核大小各部相同,一般采用3,4,5大小的卷积核。
tensorflow实现
原文参考这里
Embedding layer
with tf.device('/cpu:0'), tf.name_scope("embedding"):
W = tf.Variable(
tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0),
name="W")
self.embedded_chars = tf.nn.embedding_lookup(W, self.input_x)
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)
conv + pooling
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(
self.embedded_chars_expanded,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Maxpooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_outputs.append(pooled)
dropout
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)
output
with tf.name_scope("output"):
W = tf.Variable(tf.truncated_normal([num_filters_total, num_classes], stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")
cross-entropy loss
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(self.scores, self.input_y)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
主流程:
with tf.Graph().as_default():
sess = tf.Session(config=session_conf)
optimizer = tf.train.AdamOptimizer(1e-4)
grads_and_vars = optimizer.compute_gradients(cnn.loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
sess.run(tf.initialize_all_variables())
_, step, summaries, loss, accuracy = sess.run(
[train_op, global_step, train_summary_op, cnn.loss, cnn.accuracy],
feed_dict)