本文介绍两篇论文1 2。其中第一篇是ICML2016的最佳论文。第二篇对pixelcnn进行改进,是wavenet的基础。
以下图片是condition pixelcnn生成效果。
生成单类别图像

生成单个人图像

两个人插值(熊孩子机?)

1. 基本原理
1.1 生成模型
将联合概率转化为链式概率的乘积。当前像素值有所有前面像素值决定。
\[p(image) = p(x_0, x_1, x_2 … x_n)\] \[p(image)=p(x_0)p(x_1\mid x_0)p(x_2\mid x_1, x_0)...\]使用离散值来估计像素值。最后一层网络结构使用256维softmax来表示像素取值的概率。
1.2 mask
在转化为链式概率之后,需要特别注意的是,在预测当前点像素值的时候,不能看到后面点的像素值。文中使用mask去除后面区域的影响。
在三通道图像,会将链式规则进一步转化成:
\[p(x_{i,R}\mid X_{<i})p(x_{i,G}\mid X_{<i},{x_{i,R}})p(x_{i,B}\mid X_{<i},{x_{i,R},x_{i,G}})\]预测B通道时候,可以参考RG值。预测G通道可以参考R值,预测R通道时候只能参考前面的像素值。这种规则构成了mask a。如下图所示。
![]()
本文还介绍了另一种mask:mask b。mask b既可以参考前面像素值,也能参考当前像素值。
在第一层网络之后,不再需要mask。
mask的具体形式如下:
Mask A
![]()
Mask B
![]()
2 pixelrnn & 原始pixelcnn 1
作者提出了两种结构:row lstm,diagonal BiLSTM来预测当前像素值。主要计算当前点像素值的影响区域(receptive field)来对比两种结构的不同。
![]()
上图中,左图是理想的影响区域:所有当前像素点之前的所有结点都参与到当前像素值的预测。下面分别介绍两种rnn的影响域。
2.1 row lstm
使用mask筛选出影响当前像素点的区域。以mask核大小3为例,则row lstm的影响范围如上图中图所示。从图中可以看出很多区域并不参与预测当前像素点的值。所以只用row lstm还不够。作者又提出Diagonal BiLSTM。
2.2 diagonal bilstm
沿着对角线进行计算。从上图种的右图可以看出,右图的影响区域于理想区域一致。实验结果也表明,使用该类型的网络效果更好。
2.3 原始pixelcnn
直接使用带mask的卷积操作。并使用多层网络。
在实际使用时,pixelcnn速度比pixel rnn快。但是效果略差。接下来介绍pixel cnn的改进版本。效果与pixel rnn类似,速度较快。同时加入condition来控制合成图像内容。
3 conditional cnn 2
3.1 blind spot
从上文我们知道,diagonal bilstm效果比row lstm好的一部分原因在于影响域的覆盖不同。
作者发现通过简单的带mask的cnn会有盲点(blind spot)。比如下图右图种的灰色部分。在预测当前位置像素的时候,和灰色部分不会有任何关系。

在这篇文章种,作者将cnn拆成两部分。使用vertical,hozizon cnn来进行计算。
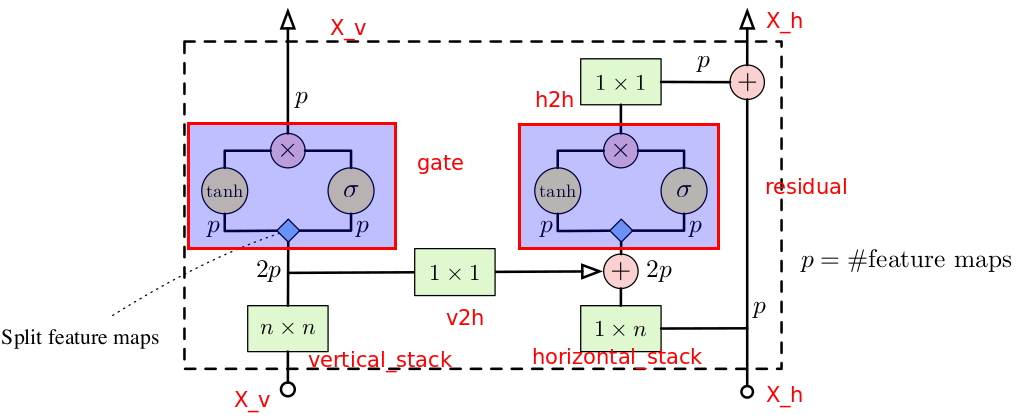
从上图的网络结构中,vertical cnn作为horizon cnn的一个分量参与计算。vertical cnn使用\(n\ast n\)的卷积核(当前行以上的n/2行),horizon cnn使用\(n\ast 1\)的卷积核。
上图红色标注部分可与后文代码一一对应。
vertical stack
对图片进行(filter_size // 2 + 1, filter_size // 2)的填充。
原来对图像的mask操作可以转化为对图像((filter_size // 2) + 1, filter_size)的区域的卷积。这样,图片所在行及其之下的区域到会被忽略。
horizontal stack
对图片进行(0,filter_size//2)填充。
当前行当前像素点之前的像素,并将上行末尾n/2-2个像素值添加当前行之前
第一层需要Mask A进行mask convolution以避免看到后面的像素。后面层次不再需要mask。每层卷积核大小是 (1*n)
3.2 gate
\[y=tanh(W_{k,f}*x)\odot \sigma(W_{k,g}*x)\]3.3 condition
\[p(x\mid h)=\prod_{i=1}^{n^2}p(x_i\mid x_1,...x_{i-1},h)\] \[y=tanh(W_{k,f}*x+V_{k,f}^Th)\odot \sigma(W_{k,g}*x+V_{k,g}^Th)\]这里的h可以是imagenet 1000类别里面的类别id,文章开头部分的图片可以看出,这个算法基本上能很好的生成每个类别的图像。
h也可以是人脸的隐含层表示。使用triplet loss(可以与center loss34比较)训练一个网络结构f,对于一张给定图片给出其latent representation h。triplet loss的作用是保证相同人的latent表示相近,而不同人距离较远。
有了上面的网络结构,对于每张图片可以有[x,h]数据对。使用pixelcnn训练\(p(x\mid h)\)。对于任意一张不在训练集种的图片x可以先通过f(x)求出h。再用pixelcnn生成出图片。
4. pixelcnn 源码分析5
该代码在mnist数据集上测试。使用10层网络,在gtx980ti上每个epoch约5分钟(12层网络跑不动),效果如下。
20次迭代,损失0.143:

100次迭代,损失0.141:

600次迭代,损失0.142:

另一份tensorflow代码,本地测试rnn效果不佳。暂时不知道原因。
pixel cnn核心代码:
vertical_stack = Conv2D(
WrapperLayer(self.X),
input_dim,
DIM,
((filter_size // 2) + 1, filter_size),
masktype=None,
border_mode=(filter_size // 2 + 1, filter_size // 2),
name= name + ".vstack1",
activation = None
)
out_v = vertical_stack.output()
'''
while generating i'th row we can only use information upto i-1th row in the vertical stack.
Horizontal stack gets input from vertical stack as well as previous layer.
'''
vertical_and_input_stack = T.concatenate([out_v[:,:,:-(filter_size//2)-2,:], self.X], axis=1)
'''horizontal stack is straight forward. For first layer, I have used masked convolution as
we are not allowed to see the pixel we would generate.
'''
horizontal_stack = Conv2D(
WrapperLayer(vertical_and_input_stack),
input_dim+DIM, DIM,
(1,filter_size),
border_mode = (0,filter_size//2),
masktype='a',
name = name + ".hstack1",
activation = None
)
self.params = vertical_stack.params + horizontal_stack.params
X_h = horizontal_stack.output() #horizontal stack output
X_v = out_v[:,:,1:-(filter_size//2) - 1,:] #vertical stack output
filter_size = 3 #all layers beyond first has effective filtersize 3
for i in range(num_layers - 2):
vertical_stack = Conv2D(
WrapperLayer(X_v),
DIM,
DIM,
((filter_size // 2) + 1, filter_size),
masktype = None,
border_mode = (filter_size // 2 + 1, filter_size // 2),
name= name + ".vstack{}".format(i+2),
activation = None
)
v2h = Conv2D(
vertical_stack,
DIM,
DIM,
(1,1),
masktype = None,
border_mode = 'valid',
name= name + ".v2h{}".format(i+2),
activation = None
)
out_v = v2h.output()
vertical_and_prev_stack = T.concatenate([out_v[:,:,:-(filter_size//2)-2,:], X_h], axis=1)
horizontal_stack = Conv2D(
WrapperLayer(vertical_and_prev_stack),
DIM*2,
DIM,
(1, (filter_size // 2) + 1),
border_mode = (0, filter_size // 2),
masktype = None,
name = name + ".hstack{}".format(i+2),
activation = activation
)
h2h = Conv2D(
horizontal_stack,
DIM,
DIM,
(1, 1),
border_mode = 'valid',
masktype = None,
name = name + ".h2hstack{}".format(i+2),
activation = activation
)
self.params += (vertical_stack.params + horizontal_stack.params + v2h.params + h2h.params)
X_v = apply_act(vertical_stack.output()[:,:,1:-(filter_size//2) - 1,:])
X_h = h2h.output()[:,:,:,:-(filter_size//2)] + X_h #residual connection added 对位相加
combined_stack1 = Conv2D(
WrapperLayer(X_h),
DIM,
DIM,
(1, 1),
masktype = None,
border_mode = 'valid',
name=name+".combined_stack1",
activation = activation
)
combined_stack2 = Conv2D(
combined_stack1,
DIM,
out_dim,
(1, 1),
masktype = None,
border_mode = 'valid',
name=name+".combined_stack2",
activation = None
)
pre_final_out = combined_stack2.output().dimshuffle(0,2,3,1)
生成图片机制
X = T.tensor3('X') # shape: (batchsize, height, width)
X_r = T.itensor3('X_r') #shape: (batchsize, height, width)
input_layer = WrapperLayer(X.dimshuffle(0,1,2,'x')) # input reshaped to (batchsize, height, width,1)
pixel_CNN = pixelConv(
input_layer,
1,
DIM,
name = model.name + ".pxCNN",
num_layers = 2,
Q_LEVELS = Q_LEVELS
)
model.add_layer(pixel_CNN)
output_probab = Softmax(pixel_CNN).output()
cost = T.nnet.categorical_crossentropy(
output_probab.reshape((-1,output_probab.shape[output_probab.ndim - 1])),
X_r.flatten()
).mean()
output_image = sample_from_softmax(output_probab) #按照概率采样。所以生成的图片会不一样
generate_routine = theano.function([X], output_image)
def generate_fn(generate_routine, HEIGHT, WIDTH, num):
X = floatX(numpy.zeros((num, HEIGHT, WIDTH)))
for i in range(HEIGHT):
for j in range(WIDTH):
samples = generate_routine(X)
X[:,i,j] = downscale_images(samples[:,i,j,0], Q_LEVELS-1) #每次预测一个像素
return X
X = generate_fn(generate_routine, 28, 28, 25)
注意,具体代码还包含了量化方案。
输入数据先量化到0-level,再降到0-1数据。输出到0-4,生成图片时候再降到0-1以输出
x_test_r: 0-4 x_test: 0-1。 而神经元的输出就是0-4,标注数据是x_test_r,所以可以直接使用交叉熵来进行优化.在theano计算交叉熵时候,如果真实数据是一个整数,则默认自动转换为one hot形式。