在微博上看到thulac的宣传其评测数据,在速度和准确性上都挺不错1。就看了其参考论文Punctuation as Implicit Annotations for Chinese Word Segmentation,想法倒是挺好的,但是跟代码实现完全没有关系。github仓库没有任何相关的算法说明,词典也是加密的,存在大量复制黏贴状况,应该是多人维护,水平参差不齐导致的。
本文先介绍其引用论文的做法,再介绍怎么破解词典加密。至于代码中的算法,暂时放弃。。
论文
现在常用的做法是把分词当做一种分类任务。对每个字分别给一个b,m,e,s标签,分别用来表示词语的开头,中间,结束,以及单字成词。基于crf的分词可以参考这篇文章
模型
本文提出另一种表示方法,用L,R分别表示词语的左右边界。之所以用LR表示,是因为LR信息很容易从标点符号获得。
\[b=L\bar{R}, m=\bar{L}\bar{R}, e=\bar{L}R, s=LR\]其中\(\bar{L}\)表示非\(L\), \(\bar{R}\)表示非\(R\)
对于一个句子\(S=c_1c_2…c_n\),要获得其对应的标注序列\(T=t_1t_2…t_n\)。
\[P(T\mid S)=\prod_{i=1}^{n}Pr(t_i\mid context_i)\]其中\(context_i\)表示\(c_i\)附近的四个字(前后各两个)。
本文采用最大熵来计算训练属于每个类别的概率。

具体算法
论文想通过训练\(L,R,\bar{L},\bar{R}\)来获得b,m,e,s的概率。论文进一步假设\(L,R\)概率相互独立。

至此,其实需要的就是大量<context, 标签>的数据。然后训练最大熵模型。
训练数据
论文中训练数据的获得很巧妙。也是本文最重要的创新点。以标点符号为信息,想法很好。
正样本
根据标点符号,可以直接给出是否L,R。如下表所示:

从上表可以看出,阳,椰 在分句句首或者标点符号后,所以标记为L,媚,风 在标点符号前,所以标记为R
上表转化为<context, label>数据,如下表所示:

表中\(c-2, c-1,c0, c1, c2\)分别表示当前字前两个字,前一个字,当前字,下一字,下两个字。以此类推。
负样本挖掘
有了正样本之后还得有负样本。本文引入一个简单的测试,来确定是否负样本。

上面这个公式的用来判断是否是单个字的概率大于其他概率。如果是的话,那么这个字应该同时是\(LR\)的正样本,否则,应该是\(L\bar{R}\),\(\bar{L}R\).
测试流程图:
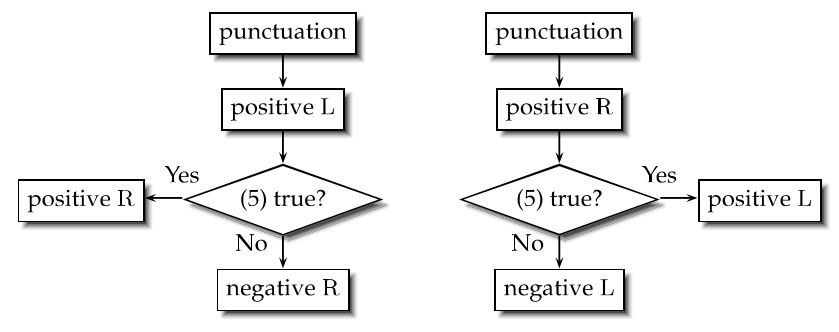
将表2的样本扔到测试种,可以增加以下样本:


论文总结
论文评测在各个数据集上表现似乎不错。想法也挺巧妙的。但是,缺点也很明显,
- 浪费了大量的数据:如上两图所示,正负样本的挖掘都针对分句边沿字(阳椰媚风)。
- 无法对\(\bar{L}\bar{R}\)进行有效的估计。
字典解密
代码没注释没文档,数据又加密。完全无从看起。
看了一下其数据读取方式,简单做了一个解密。希望对理解代码有帮助。
加密方式
c++代码就不说了,很不整洁。以python代码为例子:
def getInfo(self, prefix):
ind = 0
base = 0
for i in range(len(prefix)):
data = self.dat[2*ind]
ind = self.dat[2 * ind] + ord(prefix[i])
print prefix[i], ord(prefix[i]), data, ind, self.dat[2*ind+1], base
if((ind >= self.datSize) or self.dat[2 * ind + 1] != base):
return i
base = ind
return -base
观察输出:
天 22825 0 22825 0 0
安 23433 287246 310679 22825 22825
门 38376 275960 314336 310679 310679
每个节点i包含两个整形数字[2i, 2i+1]分别记位[ind, base],dat[index]+新字unicode,可以获得指向下一个的地址。如果指向成功,则在下一个的base位置,指向上一个的地址。。。
比如输入天安门:
- 天 unicode是22825. dat[22825]取值为0,ind=22825,base=22825
- 安 unicode为23433,dat[222825]值为287246. 新的ind为310679,同时验证了dat[2310679+1]的base值确实是22825,所以天安可以作为一个词。ind,base为310679
- 门 unicode为38376. dat[2310679]值为275960。新ind为38376+275960=314336,验证不超出数据集大小,并且dat[2314336+1]的base值确实是310679。所以天安门的确是一个词 …
以此类推。
解密
从上面的执行方式可以看出,dat文件基本上保存的是一棵树。而且为了保密,在树节点上并没有保存真实unicode信息。所以一种做法就是遍历。把unicode码试出来[应该有更好的方式]。
def do_crack(self, depth, base, data_size, word):
depth = depth + 1
ind = base * 2
if base > data_size or depth > 8:
return [word]
else:
words = []
for j in xrange(1, data_size):
index = self.dat[ind] + j
if index < data_size and self.dat[2 * index + 1] == base:
word = word + unichr(j)
base = index
words = words + self.do_crack(depth, base, data_size, word)
else:
continue
if len(words) == 0:
return [word]
else:
return words
def crack(self):
self.crack_fid = open(self.crack_name, 'w')
data_size = self.datSize
for i in xrange(1, data_size):
if self.dat[i*2+1] == 0: #begin word
word = unichr(i)
base = i
result = self.do_crack(1, base, data_size, word)
for w in result:
self.crack_fid.write(w+"\n")
self.crack_fid.close()
-
https://github.com/thunlp/THULAC ↩