基础篇
HMM语音合成的整体流程
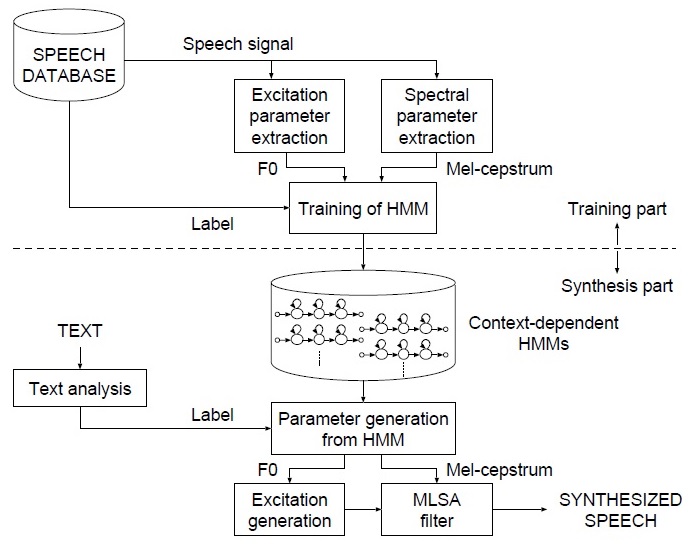
语音合成需要提取F0和mfcc特征,并对文本提取标注信息,从而训练HMM模型。 对于新的句子,需要先提取标注信息,再输入到HMM模型中,或者声学参数(F0,mfcc)等,再通过STRAIGHT等算法,将这些参数还原为声音。参考1
通常需要将文本先转化为发音单元,称为transcript。 最小的单元称为音素。现在通用的模型是把一个音素分为3个状态,分别用来模拟音素的开始、持续、结束。
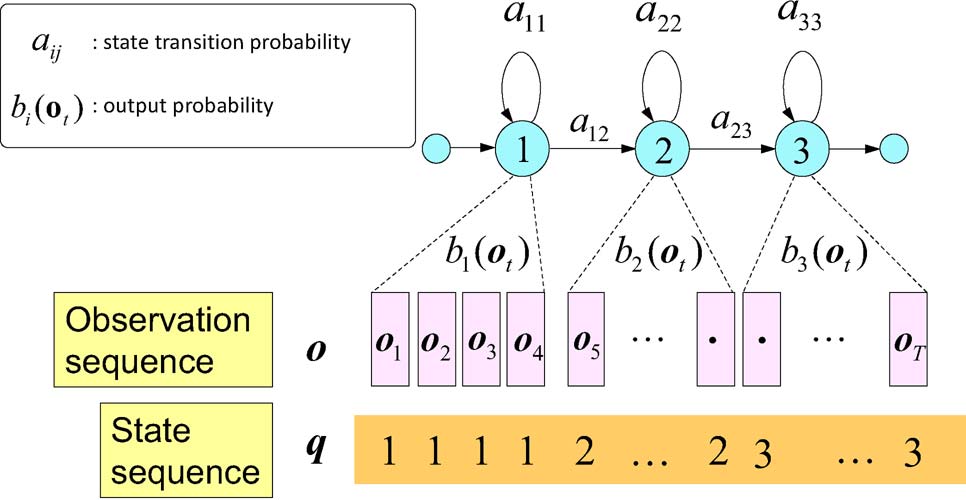
在声音序列中,将声音进行分帧。每帧对应一个状态。每个音素可能持续一定的时间, 所以上图中的q有重复的1,2,3表示每个状态的持续时间。(在htk中会将以上序列称为5状态hmm, 前后两个状态没有发射概率。中间三个状态标号分别为2,3,4).
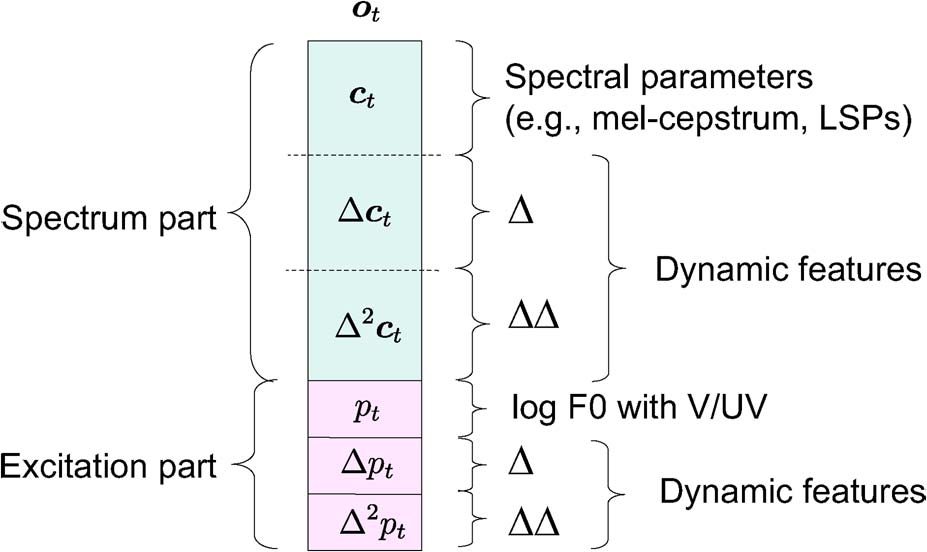
这里观测序序列除了包括F0, mfcc这些静态特征。还包括delta F0, delta delta F0 等动态特征。
在单音素hmm模型中,每个状态对应大量的观测值, 需要用个模型对状态到观测进行建模。一般选用多维高斯模型。之所以用多维,是因为观测值是多维的。 观测模型为:

在训练和合成的时候:
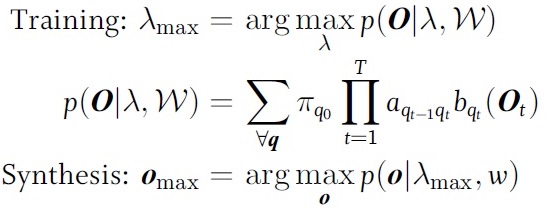
具体合成时:

上面只是单个音素的模型,在句子中,通常的做法是将每个词对应的音素模型从左到右连接起来构造HMM网络。下图是a, i两个音素构造的hmm网络,在合成的时候需要决定:每个状态对应的观测,每个音素对应多少个状态(duration模型)。
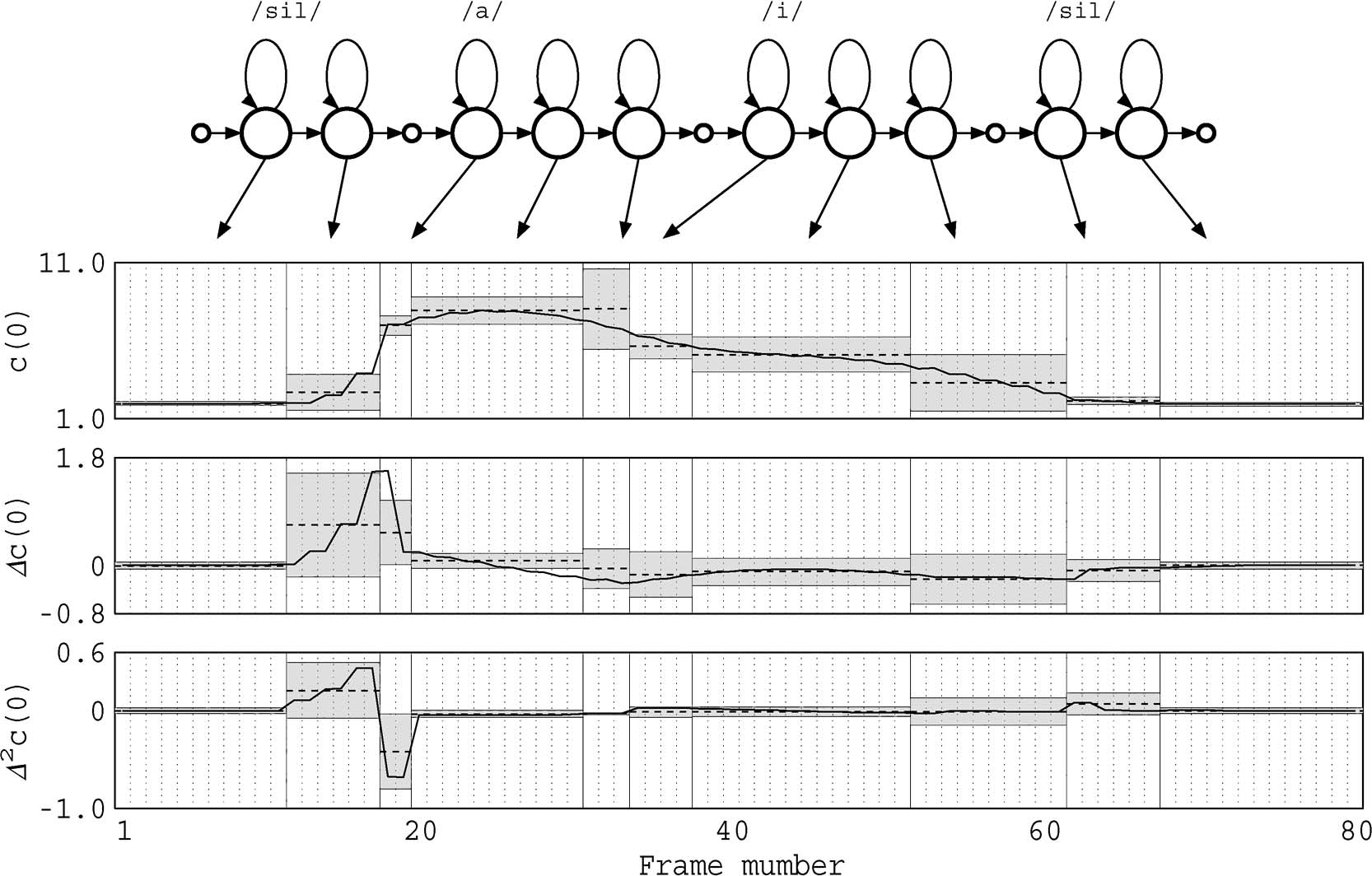
HMM模型 Baum-Welch训练
在训练的时候,有的直接将整个词训练称为whole word模型;有的将词划分为音素再训练,则称为sub-word模型,这种训练也称为embeded training。参见2 p7

Whole word模型将使用的整个词学习与声音的对应关系。最新基于深度学习的方法这样做取得不错的效果。HMM通常用的都是embeding training。 后文默认都指的是这种规模。 在上图中右图, 训练的初始化有两种方式, 一种是hInit + hres的方式,一种是HCompv的方式。第一种方式需要部分已经标注,对齐的数据。而第二种方式是我们通常使用的方式。即:将音素和观测训练按均匀等分的形式进行划分。然后使用全局的均值和方差作为每个音素模型的均值,方差。 这种初始化方法也成为flat-start。
对于观测模型:
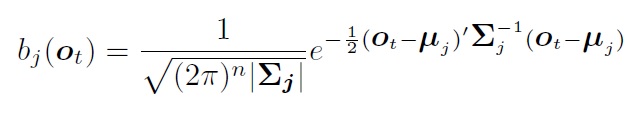
如果每个状态对应的观测值都已经标注好(对齐), 那么直接可以求得均值和协方差:
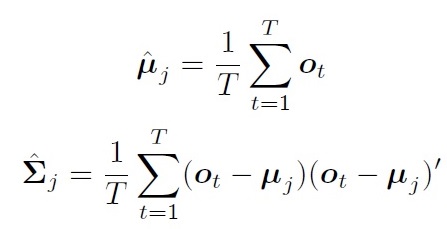
但是实际上,很难获得对齐数据。即使人工标注,也会容易造成不一致。
下面介绍通过Baum-Welch 训练算法.
在Baum-Welch 算法中,假设每个观测值都可以用任意状态产生。 将第t帧属于第j状态的概率标记为:\(L_j(t)\)
均值方差估计为:
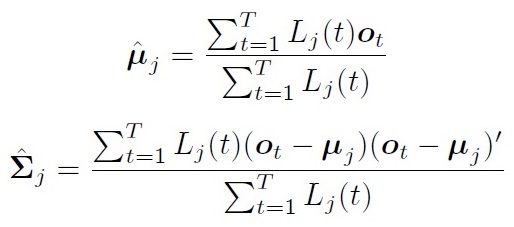
HMM前向算法:
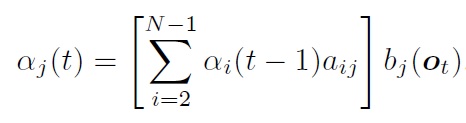
后向算法:
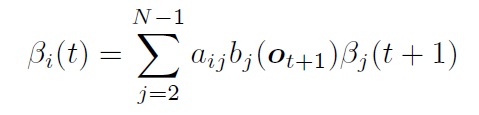
将第t帧属于第j状态的概率为:

转移概率的更新比较复杂。需要分别计算进入概率,出去概率, 内部转移概率, 从入口直接到出口概率。参考2 p135.
迭代以上过程,直到达到结束条件。(average log pro不再优化)
Viterbi training(forced alignment)
Baum-Welch training中,把每个观测值都可以由任意状态产生,通过概率控制其影响程度。称为软边界。而Viterbi training 中,寻找一个最佳路径,每个观测值只能属于一个状态,称为硬边界, 所以也成为forced alignment。
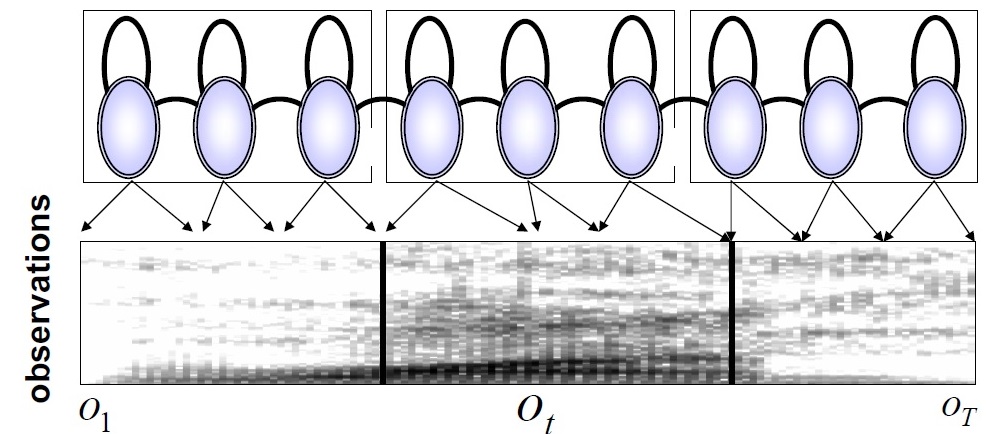
在上图中,对于一个给定的句子,其单词序列是固定的,包含哪些状态是固定的。只是需要寻找每个状态的持续时间(具体状态序列)。 而Baum-Welch training要先找到单词序列,才能找状态序列。从下图中可以看出,Viterbi算法对于某个观测值,要么属于当前状态,要么属于下一个状态,只有两个方向。而Baum-Welch training则需要考虑各种可能,所以Baum-Welch更耗时。参见3

高级篇
到目前为止,最基本的 hmm语音模型已经介绍完了。可以用来做语音合成,语音识别。但是,这种简单的模型还不够鲁棒,不够完善。后面介绍的context-dependent模型,状态绑定,duration模型,GMM,stream是为了提高鲁棒性。输出模型GV,F0是语音合成方面需要处理的问题。
context-dependent model和状态绑定
上文介绍的都是基于单音素的模型(monophone),即每个音素对应一个hmm。这样无法反映每个音素在不同的上下文环境中发声情况不同。所以一般使用双音素模型(biphone), 三音素模型(triphone) 例子:

考虑到词内、词间的不同,三音素模型的划分又有不同。(可能的优化点,与停顿相关)

现在更常用的是三音素模型,下文默认都是使用三音素模型。 在三音素模型中,需要注意的是这里每个模型(例如B-R-AY)对应的是一个hmm模型,对应三个状态,而不是多个不同的音素模型(B,R,AY)进行拼接。 这样使用三音素模型可以将音素从不同的上下文区分开来。但是也造成了组合爆炸。也就是很多组合可能根本就没出现,或者很少出现,无法对齐进行参数估计。所以,需要引入聚类,将相似的状态进行聚类。需要注意的是,聚类的时候,两个模型分别对应的3个状态)很少一模一样, 很有可能只是部分相同。
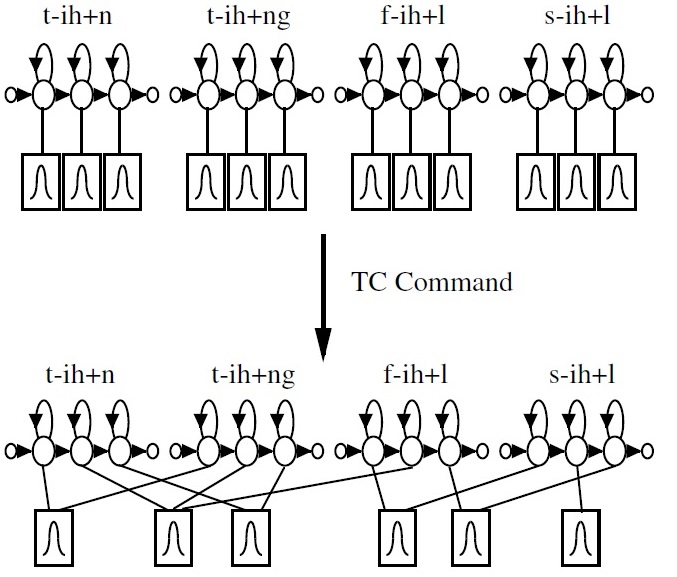
下面考虑最简单的绑定:

在HTK中TI表示绑定。上面的例子是将每个模型中间音素相同的第三个状态进行绑定。将设以某个音素为中间音素的模型数的平均数为100。 那么在绑定之前共有300个状态,通过绑定之后则变成201个状态。这种方法虽然减少了状态数,但是不够鲁棒,而且无法解决数据不足的问题。 基于学习的绑定有:基于聚类的绑定和基于决策树的绑定。参见2 p153 基于聚类的方式先假设所有模型都互不相同,然后不断合并距离在一定范围内,数量少的模型。 基于决策树的绑定是先假设所有模型属于同一个类,然后通过决策树的问题,不断分裂,最后达到相同叶子节点的模型分作一类,一起训练。

duration 模型和hsmm
使用转移模型,使用随机数决定下一个状态是什么,虽然在统计上合理,但是在实际中,很有可能造成剧烈的抖动。实际的声音,往往存在连续性,而且随着时间的增长,同个状态的出现概率呈指数衰减,而不是相互独立的。 一般使用explicit duration model来对duration进行建模。参考4
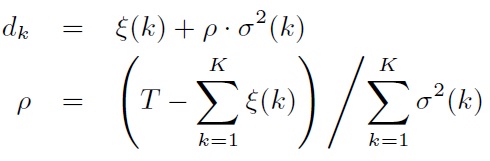
对于给定的合成时间T, 可以求解各个状态的duration: 而上式的ρ可以控制语速。
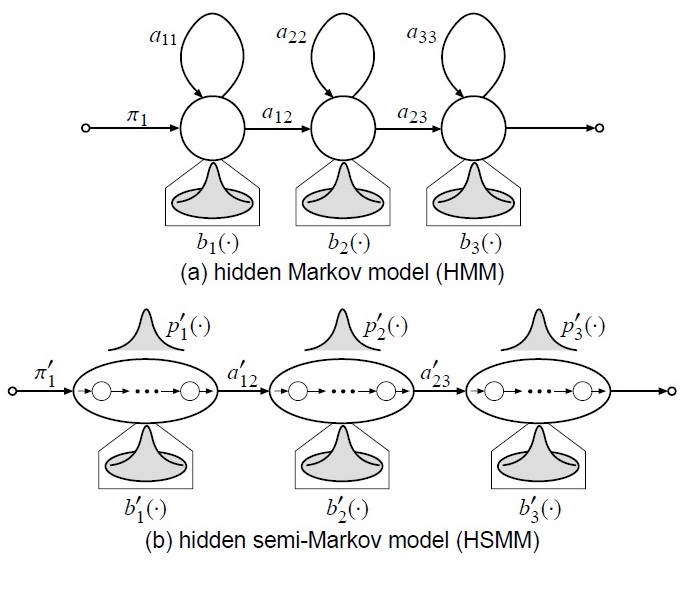
上面的使用模型的主要问题是explicit duration model只在合成的时候使用,而并没有参与训练。Tokuda等人又提出HSMM,其实就是将explicit duration model加入训练中,获得更好的结果。HSMM与HMM不同之处在于用高斯模型对duration进行建模。公式推导见论文5。
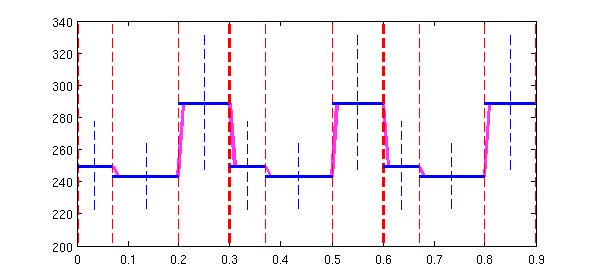
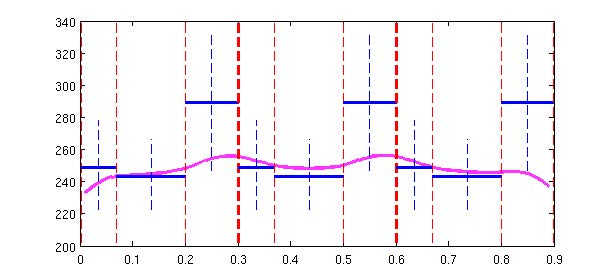
输出模型GV
给定状态到输出参数, 需要额外的处理,否则会使得输出值都是状态的高斯模型的均值,而状态边界又变化太大。参考6

其他: GMM, stream, F0不连续性
使用混合高斯模型使得参数更加准确,使用stream对f0, mfcc等统一建模。使用MSD-HMM处理F0的不连续性。
参考文献:
-
Tokuda K, Nankaku Y, Toda T, et al. Speech synthesis based on hidden Markov models[J]. Proceedings of the IEEE, 2013, 101(5): 1234-1252. ↩
-
Practical HMM Training (for Speech Recognition) [online] ↩
-
Yoshimura T, Tokuda K, Masuko T, et al. Duration modeling for HMM-based speech synthesis[C]//ICSLP. 1998, 98: 29-31. ↩
-
Zen H, Tokuda K, Masuko T, et al. Hidden semi-Markov model based speech synthesis[C]//INTERSPEECH. 2004. ↩
-
Tomoki T, Tokuda K. A speech parameter generation algorithm considering global variance for HMM-based speech synthesis[J]. IEICE TRANSACTIONS on Information and Systems, 2007 ↩