插播今天看到的一篇论文1。这篇论文正好做的事情跟我去年做的实验差不多。所以特意关注了。
文章写的效果很厉害,还提供了网页试听,当时我就信了。等我看完文章再去试听,效果实在不敢恭维,orz。不过也算提供了新思路。
背景
tts研究有个重要的方向是adapt。就是希望用户提供少量的句子,就能训练处效果。传统的方式一般是通过微调一个已经训练好的大网络来进行的。本文所说的voice clone意思就是只要用户少量的句子(甚至一句), 就可以合成语音来。voice clone包含我们通常用到的adapt和本文新提出的speaker encoding。
在训练tts的时候,我们总可以对输入增加某些特征来标识这是属于哪个角色,当然也可以用ivector特征来表达。从deep voice2把speaker embedding引入来训练多角色tts。所谓speaker embedding就是一个可学习的低维向量。与通常碰到的word embedding差不多一个意思。
在实际的应用中,有一种需求:说话方式和说话音色的分离,然后任意组合。比如说,我有蜡笔小新的录音,有普通用户A的录音,现在想用A的音色用蜡笔小新的说话方式发音。之前我用gan做过实验,效果不好。本文居然号称能搞定!我们稍后看看怎么做的。
voice clone
所谓voice clone就是,在拿到一个新的没见过speaker的语音之后,需要做点什么来让后面的生成步骤可以生成这个speaker的语音。最最传统的方式,就是把这些数据加进去微调得到新模型,这也就是clone了。
本文对voice clone 提出了两个模型:
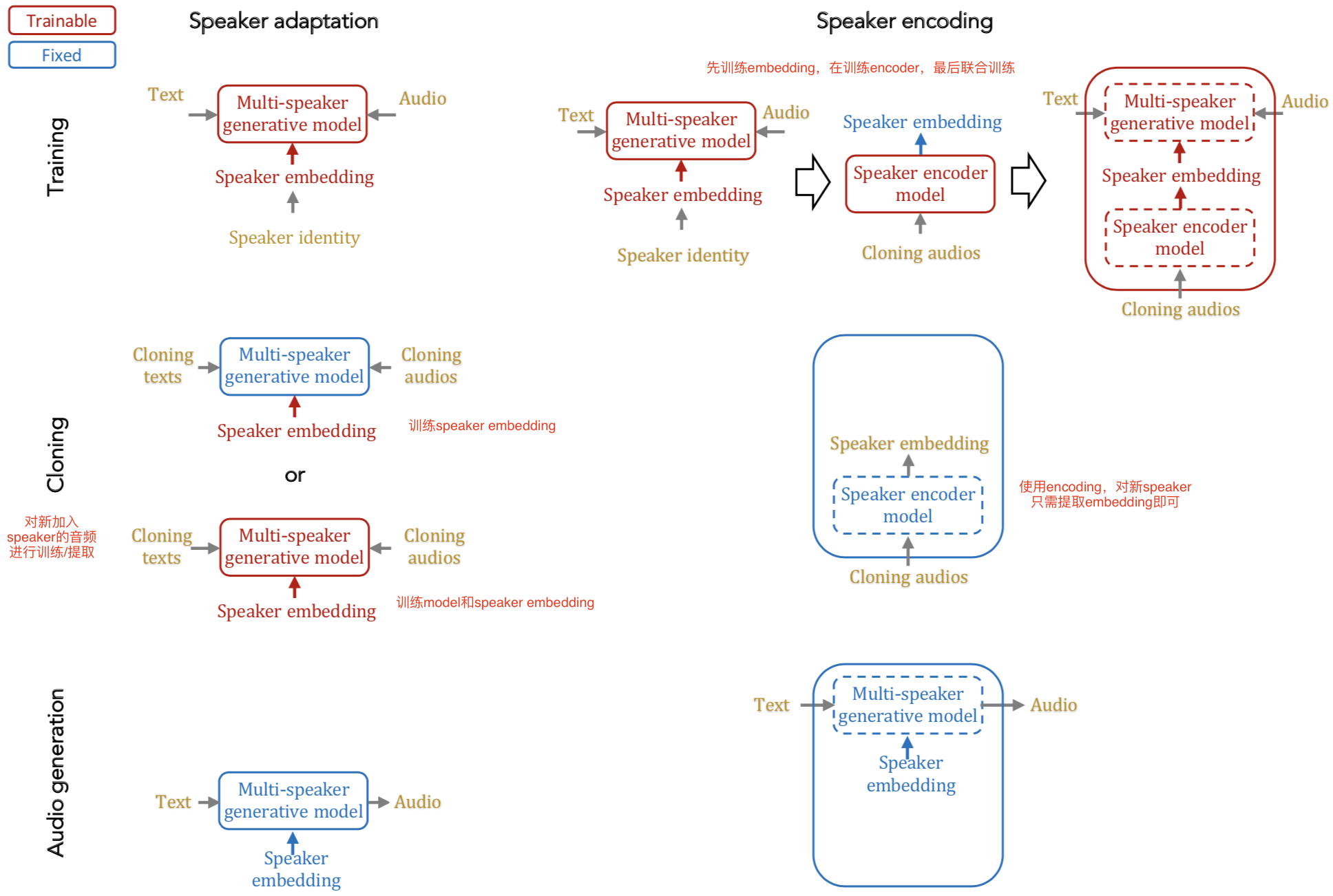
- adapt。跟通常所用的adapt不同的是,本文是通过添加speaker embedding层来训练多speaker网络。然后在clone的时候将新speaker的声音,输入网络中,提取speaker embedding,同时微调整个网络(也可以不微调)。最后用这个clone过的模型来生成语音
- encoding。增加一个独立的speaker encoding模型。为了减少训练难度,在训练阶段先训练一个正常的多speaker模型。然后用这个模型获得speaker embedding来训练一个新的speaker encoding模型。最后联合训练进一步微调。在clone阶段,只需要简单的请音频输入speaker encoding网络就直接可以输出speaker embedding了。最后用这个speaker embedding来生成语音。
框架图如下。中文标注是我添加的。
文章公式写的很复杂,实际都很简单。网络结构也是现在tts常用的: residual + gated linear unit。这些就不做具体介绍了。
结果
本文号称speaker encoding效果很好,adapt效果很好。先姑且相信。
最令人吃惊的是:
BritishMale − AveragedMale + AveragedFemale = British female speaker
上面这些都是对应角色的speaker embedding。我们来解释一下哈: 男布什的speaker embedding - 平均男性的embedding + 平均女性的embedding获得的embedding输入网络中,可以获得女布什的声音。
这不就是传说的词向量吗?如果真的能这么做到的话,那么前面说的普通用户版的蜡笔小新就能实现了。
抱着将信将疑的态度打开了试听网页,大部分音色不对,音质不好(与我用ivector作为特征的结果类似)。至于女布什的声音一样挺烂的,没听出来明显的角色感。
也有可能我的打开方式不对??
todo: 回头添加ivector训练结果
参考文献
-
Sercan O. Arik, Jitong Chen, Kainan Peng, Wei Ping, Yanqi Zhou,Neural Voice Cloning with a Few Samples. arXiv:1802.06006 ↩