今天无意中看到阿里tts团队即将发在ICASSP 2018的论文dfsmn1。基本上就是用一种新的fsmn结构来替代lstm,在不损失效果的前提下,达到减小模型大小,加快训练预测速度的目的。要读懂这篇论文,需要先对fsmn2,cfsmn3有所了解。本文介绍这三篇论文。
fsmn
Shiliang Zhang等人2015提出fsmn(feedforward sequential memory networks) ,讯飞当时的最佳结果似乎是基于这个结构,具体参考这篇pr。
我们先来看一下这个网络张什么样子的。
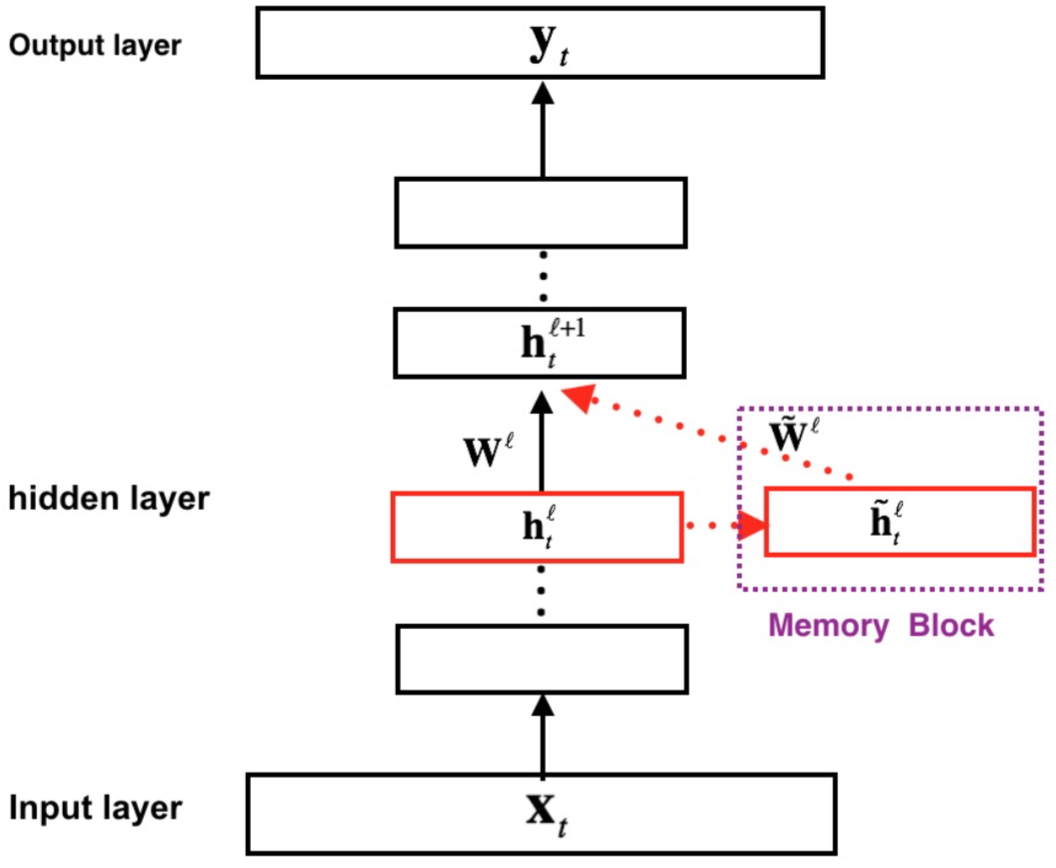
从上图可以看到,对于每个输入$X_t$, 经过多层网络之后获得$Y_t$. 如果没有虚线框部分,那么就跟普通的dnn没有区别了。重点还是在虚线框部分,这被称为memory block。
memory block来保存历史信息。用blstm和bfsmn来比较,我们可以更好的知道两者的区别(以语音识别为例):
- blstm由于rnn结构的特性,需要得到整个完整语音输入,再进行双向lstm计算。
- bfsmn在后向的时候,不需要或者完整输入,只要或者之后的部分信息就够了。比如说,语音识别延时个0.2秒,这部分信心足够后向fsmn使用了。
接下来我们具体列一下fsmn的计算公式, t时刻 $l$ 层的输出表示为$\mathbf h_t^l$:
\[\tilde{\mathbf h}_t^l=\sum_{i=0}^{N}a_i^l\cdot \mathbf h_{t-i}^l\]其中$a_i^l$是与时间无关的系数。当然也可以是向量。如果是向量, 则换成对位相乘
\[\tilde{\mathbf h}_t^l=\sum_{i=0}^{N}\mathbf a_i^l\odot \mathbf h_{t-i}^l\]上式只是单向形式,对应双向表示为:
\[\tilde{\mathbf h}_t^l=\sum_{i=0}^{N_1}a_i^l\cdot \mathbf h_{t-i}^l+\sum_{j=1}^{N_2}c_j^l \cdot \mathbf h_{t+j}^l\] \[\tilde{\mathbf h}_t^l=\sum_{i=0}^{N_1}\mathbf a_i^l\odot \mathbf h_{t-i}^l+\sum_{j=1}^{N_2}\mathbf c_j^l \odot \mathbf h_{t+j}^l\]通过当前层block memory的计算,下一层的$为:
\[\mathbf h_t^{l+1}=f(\mathbf W^l\mathbf h_t^l+\tilde{\mathbf w}^l\tilde{\mathbf h}_t^l+\mathbf b^l)\]cfsmn
Shiliang Zhang等人对fsmn进一步改进,提出cfsmn(compact feedforward sequential memory networks)。将模型缩小到原来的60%,速度提高7倍。同时保证效果比blstm更好。
cfsmn结构如下图所示。
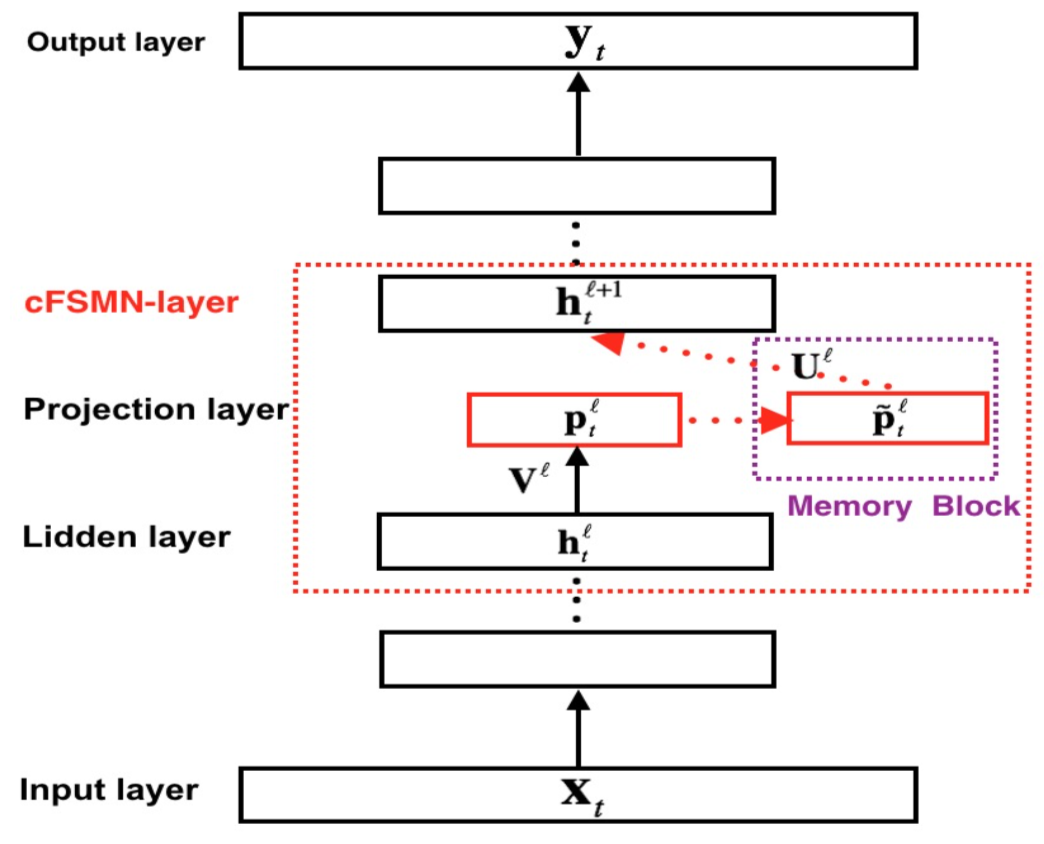
从上图可以看出,基本思路就是将$\mathbf h$通过$\mathbf V^l$映射到低维空间,再在低维空间上做memory block的事情,最后对再映射回$\mathbf h$空间。
\[\mathbf p_t^l=\mathbf V^l\mathbf h_t^l+\mathbf b^l\] \[\mathbf{\tilde{p}}_t^l=\mathbf p_t^l + \sum_{i=0}^N\mathbf a_i^l \odot \mathbf p_{t-i}^l\]双向形式为:
\[\mathbf{\tilde{p}}_t^l=\mathbf p_t^l + \sum_{i=0}^{N_1}\mathbf a_i^l \odot \mathbf p_{t-i}^l+\sum_{j=0}^{N_2}\mathbf c_j^l \odot \mathbf p_{t+j}^l\]映射回原空间:
\[\mathbf h_t^{l+1}=f(\mathbf U^l\mathbf{\tilde{p}}_t^l+\mathbf b^{l+1})\]dfsmn
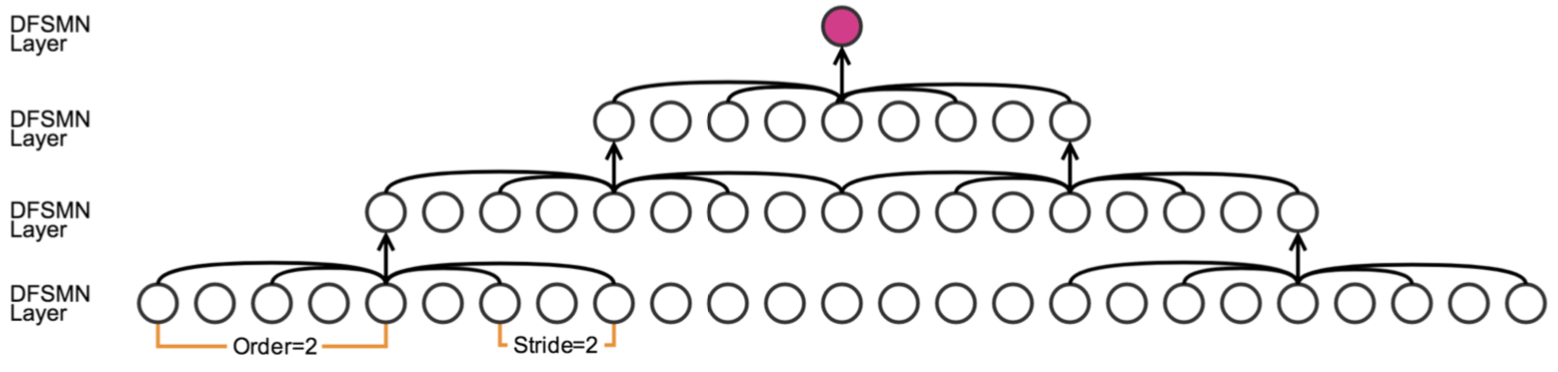
- skip connections
- order, stride
参考文献
-
Mengxiao Bi, Heng Lu, Shiliang Zhang, Ming Lei, Zhijie Yan, Deep Feed-forward Sequential Memory Networks for Speech Synthesis, ICASSP 2018 ↩
-
Shiliang Zhang, Cong Liu, Hui Jiang, Si Wei, Lirong Dai, and Yu Hu, “Feedforward sequential memory networks: A new structure to learn long-term dependency,” arXiv preprint arXiv:1512.08301, 2015. ↩
-
Shiliang Zhang, Hui Jiang, Shifu Xiong, Si Wei, and Li-Rong Dai, “Compact feedforward sequential memory networks for large vocabulary continuous speech recognition.,” in INTER- SPEECH, 2016, pp. 3389–3393. ↩