本文介绍ssd1。ssd在2015年12月第一次提交到arxiv,到今天还是非常活跃。也出现了不少论文对ssd进行修改,不过基本上都是换汤不换药。
ssd的主要贡献如下:
- 多层feature map预测
- 沿用faster rcnn[^faster rcnn]的anchor box,不过使用多尺度,多长宽比的anchor box
- 使用卷积层来做位置、类别预测
- 使用改进的multibox的box匹配策略。
- 复杂有效的数据扩充
接下来我们对以上各个特性逐个讲解。最后我们用一张图作为总结。
multiscale feature map
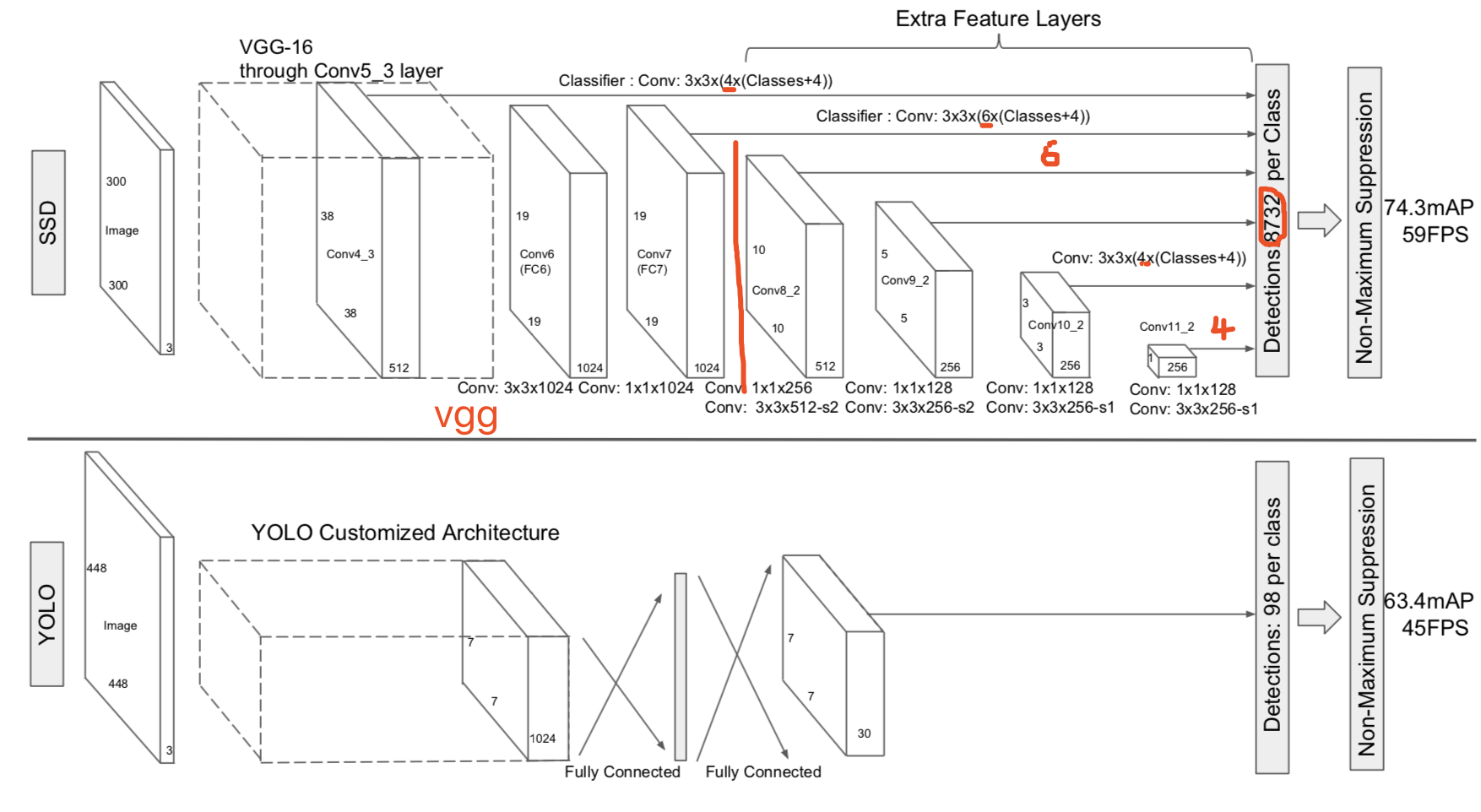
上图是ssd和yolo的对比图。这里给出的是yolo1的图,map显得低很多。实际上yolo2并不比ssd差。后面我们说到yolo默认指的是yolo2。yolo基本上属于长条形,虽然中间会有一些跳跃层,但通过reorg层,并route(concat),变成正常hwc结构,最后通过全连接层输出结果。比如coco 80类,416x416的输入,最后层的输出是13x13x425.
13x13是anchors box。对于每个anchors box位置输出425维度的信息。而这425维的信息是5x(80 + 1 + 4). 5是anchor boxes尺度数目。80是类别,1是objectness score, 4是坐标。也就是yolo2是类别和坐标统一预测的。
而ssd是在网络结构上与yolo明显不同。首先声明ssd的基础网络结构是可以变的。原论文用vgg16作为基础网络。上图红线左边的部分是vgg网络,从图中可以看出,ssd取conv4_3和conv7的输出,加上卷积层用于位置预测。同时对conv7的输出进一步卷积,通过继续卷积下采样,获得其他尺度的特征图,由这些图来进行位置预测。从而拥有多尺度的能力。
anchor boxes
ssd anchor boxes的设置与faster rcnn不大一样。这里考虑不同的长宽比和尺度。对于每个feature map的参数也有不一样。
上图用红线部分画出来的数目表明每个尺度是不一样的。图中有个8732是怎么来的呢?这与具体训练参数相关,通过查看作者源码,我们可以知道: 38*38*4+19*19*6+10*10*6+5*5*6+3*3*4+1*1*4=8732. 上面的38,19,10这些是每层feature map的大小。
与faster rcnn一样,位置相对于default box的编码如下:
\[t_x=(x-x_a)/w_a, t_y=(y-t_a)/h_a\] \[t_w=log(w/w_a), t_h=log(h/h_a)\] \[t_x^*=(x^*-x_a)/w_a, t_y^*=(y^*-t_a)/h_a\] \[t_w^*=log(w^*/w_a), t_h^*=log(h^*/h_a)\]其中$x$, $x_a$, $x^*$分别代表预测box,anchor box, ground-true box。
multibox
现在我们知道了有很多这些anchor box。在训练的时候,每个anchor box都能预测出一个位置。训练的时候应该优化哪些框呢?
ssd采用与multibox类似的方法。第一次用overlap最大的进行优化,后面使用overlap大于0.5的来优化。
总结
现在让我们通过下面这张图把上面讲解的东西串起来。
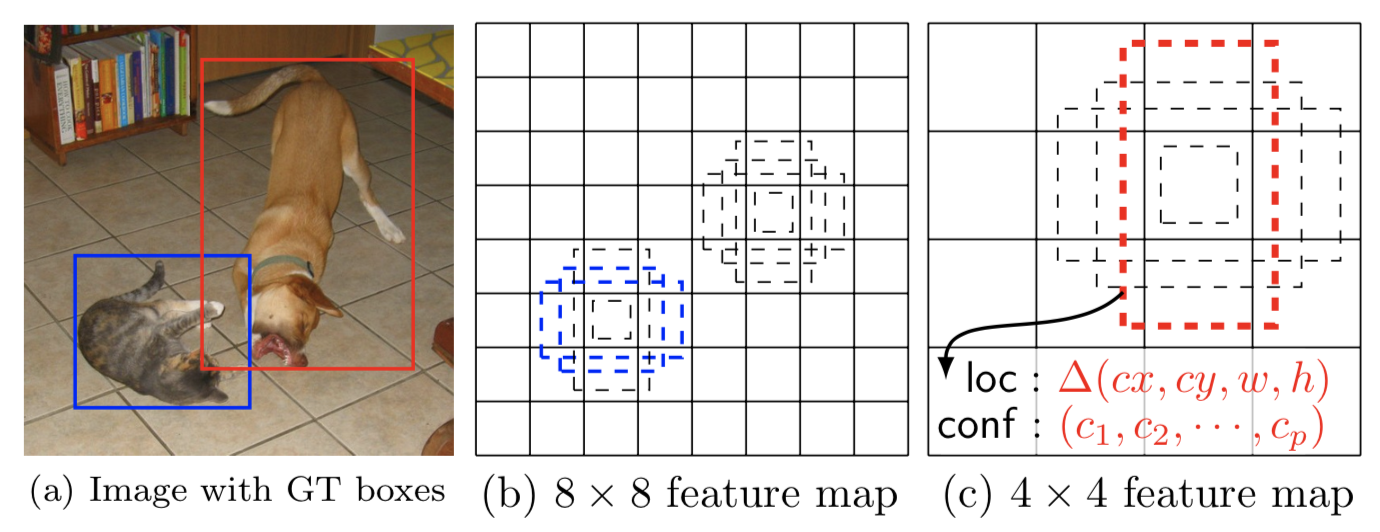
上图左边有一只猫和一只狗。假设我们使用两个scale的feature map进行预测。这两个scale的feature map分别是8x8和4x4。我们先看中间的那张图,在猫狗附近的位置重叠度最高的anchor box的位置已经画出来了。有了这些位置之后再去计算与真实框的重叠度。如果重叠度低于一定的阈值,则忽略。否则进行优化。中间图狗的位置的那几个框虽然跟狗的重叠度最高,但没有达到一定阈值,所以不做考虑。最后结果是,在8x8的feature map上有两个蓝框对毛的位置进行训练。在4x4feature map上红框部位对狗的位置进行训练。
参考文献
-
Liu, Wei, et al. “Ssd: Single shot multibox detector.” European conference on computer vision. Springer, Cham, 2016. ↩