本文介绍rfcn用于物体检测。faster rcnn之所以慢,是因为这种网络将rpn预测出候选区域之后,还需要对每个区域独立地计算类别概率和bbox位置。而本文提出的算法基本上都是对整张图像进行卷积,减少很多计算量。具体上,本文提出position-sensitive score maps 来出来不同的roi。精度与faster rcnn差不多,速度快2.5到20倍。
背景介绍
本文的背景介绍写的很好。推荐阅读。TODO: 完善这部分。
框架
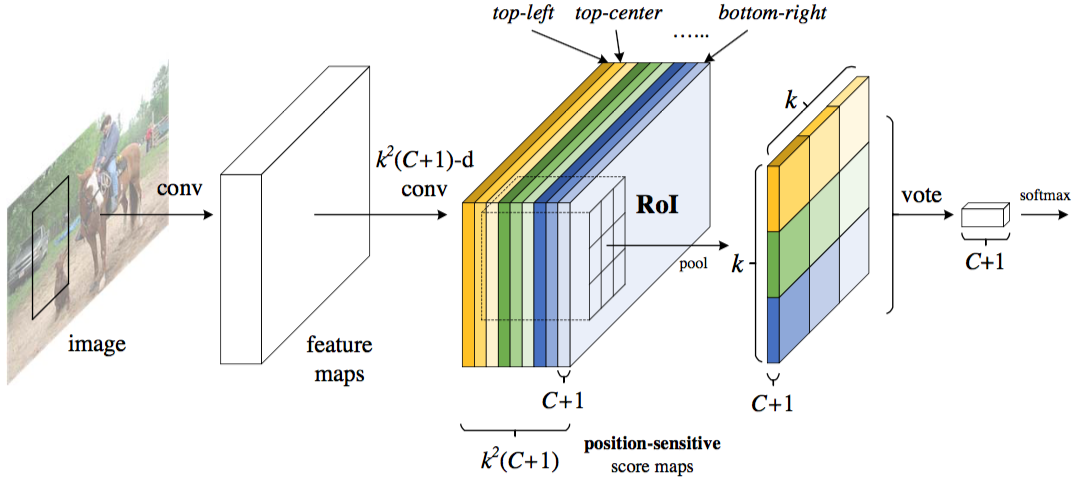
本文的idea如上图所示。对于一张图片在经过一系列卷积之后(backbone网络),faster rcnn是对上图的每个roi区域进行计算。为了防止计算,这里一次性的获得$k^2(C+1)$个特征图。可以认为一共有$k^2$个$C+1$通道的特征图。这个$k^2k$用来对物体位置进行编码,可以分别认为是物体的左上,中上,右上…右下这些位置。然后对这些特征图的roi位置进行pooling(每个特征图只有特定位置有用?岂不是浪费了计算资源?)。每个网格的pooling数值等于网格内部所有像素的平均。然后将这些$k^2$ pooling的数值进行投票,获取最终数值用来表示该位置的该类别的概率。
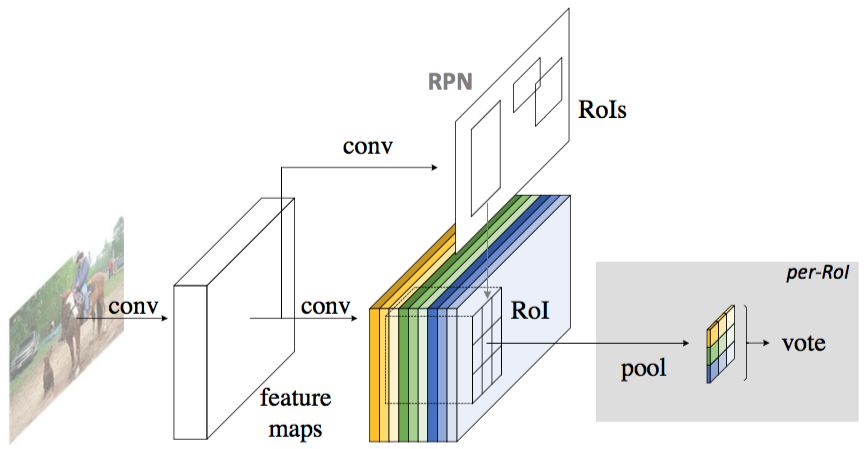
上面只是分类。还需要对框的位置进行回归。具体方法与上面类似。不同之处在于使用$4k^2$个特征图。进行pooling之后获得4个数值。用fast rcnn的方法进行解码。
细节
在实验中,使用resnet101作为基础网络。正常cnn网络经历5个stride为2的卷积,共缩小32倍。这里只缩小16倍。在conv4之前都是相同的。将conv5的第一个卷积stride改成1, 后面的所有卷积核用Atrous算法进行处理。
效果
以下两张图分别是person检测的正样本和负样本的person类score map。
正样本:

上图这个框比较好的框柱了这个小孩。$k*k$个位置的响应都比较高。最后对其进行vote(取平均),被认为是正样本。
负样本:

上图框有一些偏移。有些位置有较高的响应的,有的位置响应较低。vote结果是负样本。