- 1 AllophonesExtractor
- 2 htklabeler
- 3 LabelPauseDeleter
- 4 PhoneUnitLabelComputer
- 5 TranscriptionAligner
- 6 FeatureSelection
- 7 PhoneUnitFeatureComputer
- 8 PhonelabelFeatureAligner
- 9 Feature 管理
- 10 HMM 模型
1 AllophonesExtractor
对文本进行自然 语言处理标注, 生成结果保存在prompt_allophones。内容为参见5.
2 htklabeler
自动对齐。 结果保存在htk/lab中
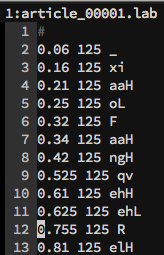
3 LabelPauseDeleter
对htk/lab中的标注文件进行校正, 删除小于阈值以下的空音。结果保存到lab文件夹。
通过以下参数设置阈值。
LabelPauseDeleter.threshold = 10
4 PhoneUnitLabelComputer
转换lab格式。 从lab读取文件, 保存到phonelab中
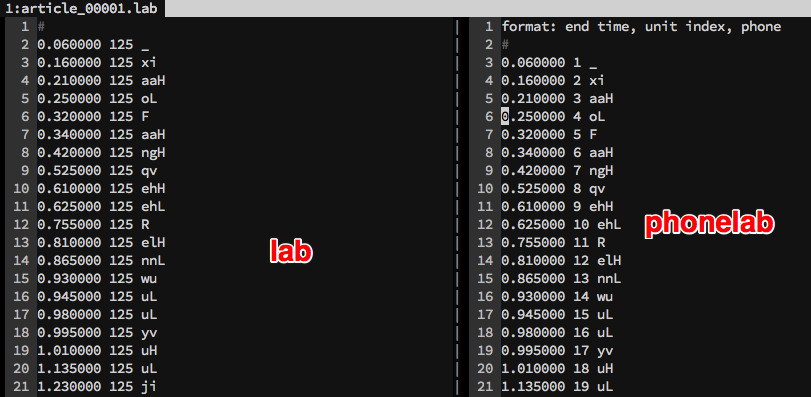
5 TranscriptionAligner
生成allophones目录。 确保生成的自然语言处理序列没有问题?
个人看法:若用户手动校正了部分对齐结果, 则这个步骤的作用是:调整自动对齐结果, 使其与手动标定相符合。
内容为:
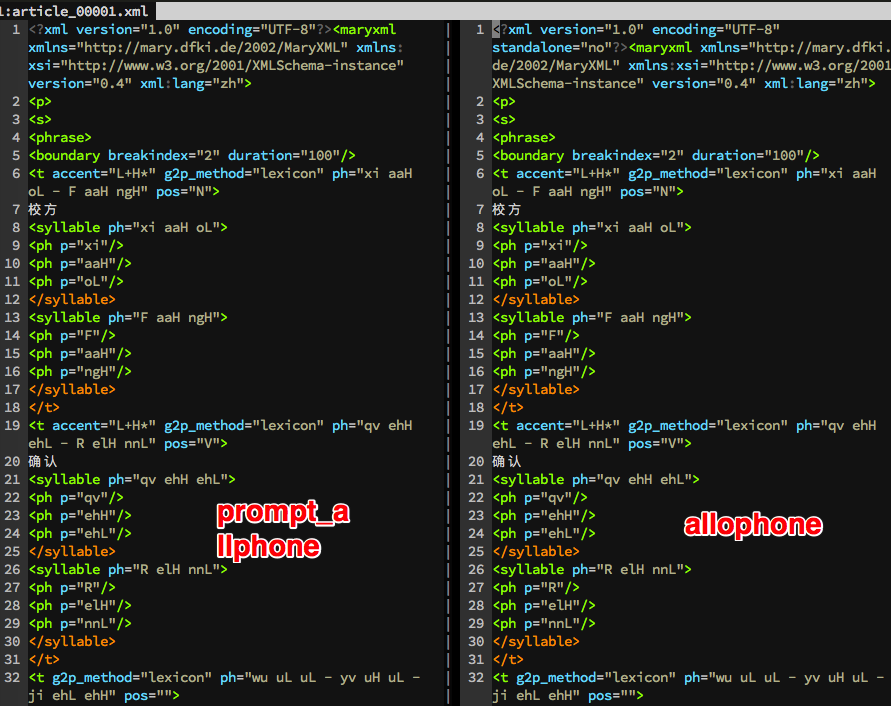
update: 2016-08-02
这一步骤的作用在于,根据自动对齐的结果,在纯自然语言处理预测的prompt_allophones的基础上添加一些停顿,并将结果写入allophones文件夹
6 FeatureSelection
生成 mary/features.txt
在FeatureprocessManager里对问题集进行注册。
在MaryGenericFeatureProcessors里对各种问题集的考察方式进行定义。处理各种特征。
以上信息都是注册在runtime里面,这里只是从那里读取,所以需要开启服务器。
7 PhoneUnitFeatureComputer
注意: 留意这里的context是词内还是词间的
从文本文件中,提取context特征。保存到phonefeatures里。
以arcticle_00001为例子,1-107 是所有句子都相同的标志。 109-207为label序列中每个音素对应的特征。209-307为其他特征。
article_00002中, 1-107与上面相同, 109-235是label音素特征。 237-363是其他特征。
从上面可以发现上面三部分中,第二部分和第三部分的长度都是相同的,所以第三个部分对应的也是音素特征。
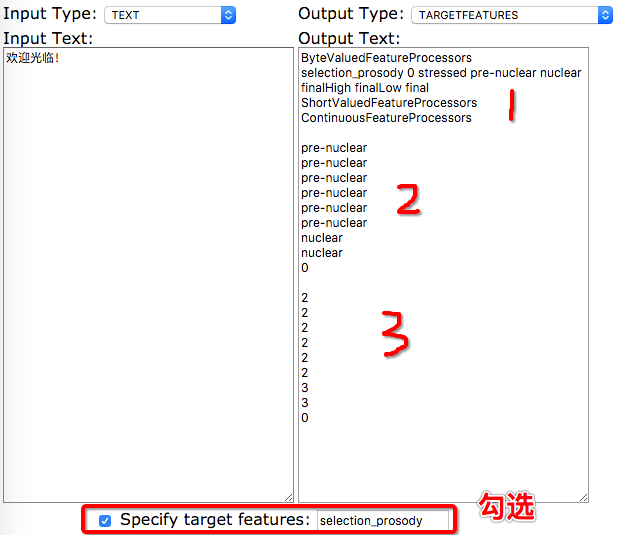
在web上勾上筛选特征,则输出的文件如上图所示。可以看出,第一个区域定义了selection_prosody特征的取值分别有 0 stressed pre-nuclear nuclear finalHigh finalLow final 七种, 分别对应到数字则是0-6。第二区域定义每个音素的selection_prosody特征。第三个区域将特征数值化。
context特征的计算也是在server上,保持合成和训练一致。 调用服务器进行特征计算,输入类型为:ALLOPHONES, 输出类型为:TARGETFEATURES, 并传入featureList指定需要计算的特征。
8 PhonelabelFeatureAligner
对phonelab里的标注文件与phonefeatures里的特征文件进行比对, 看特征文件中的序列是否正确,若不正确, 则提供手动修改的机会。
9 Feature 管理
FeatureDefinition
定义特征名字
MaryGenericfeatureProcessors
对tobiEndtone, next_cplace, next_ctype, next_cvox, next_is_pause等进行定义, 用于处理各种特征。
FeatureProcessManager
- 对tobiEndtone,next_cplace, next_ctype, next_cvox, next_is_pause等进行注册。
FeatureProcessManager管理每个特征的processors。- 在该类的定义中,featureProcessManager要么对应一种locale, 要么对应某种声音(通过registerAcousticModels函数进行设置)。
- 语言的配置文件(如zh.config)对使用哪个manager进行定义。 例如:featuremanager.classes.list = marytts.features.FeatureProcessorManager(zh)。 德文对feature进行了重定义,则在de.config中设置: featuremanager.classes.list = marytts.language.de.features.FeatureProcessorManager, 使用新featuremanager。
- Voice.java加载一个声音,就是加载phoneset, 声学模型和featureManager类名。
TargetFeatureComputer
- (featureProcessorManager, featureDefinition.getFeaturesNameds()) 计算具体值的计算。
- TargetFeatureComputer构造的时候, 将featureProcessManager的processor按照类型保存到不同的类别中。
MaryFeatureProcessor fp = manager.getFeatureProcessor(name);
if (fp == null) {
throw new IllegalArgumentException("Unknown feature processor: " + name);
} else if (fp instanceof ByteValuedFeatureProcessor) {
byteValuedFeatureProcessors.add(fp);
} else if (fp instanceof ShortValuedFeatureProcessor) {
shortValuedFeatureProcessors.add(fp);
} else if (fp instanceof ContinuousFeatureProcessor) {
continuousValuedFeatureProcessors.add(fp);
}
10 HMM 模型
HTSModel 每个音素或者context对应的模型。 HTSUttModel 句子模型, 由 HTSModel构成
HMMModel 包含HMMData(实例化为:htsData), HMMData保存hmm模型的各种数据, 包括cartreeset, gvstream等。
数据加载。

- data prepare
将hts拷贝到对应目录中。检查依赖库是否完全安装。拷贝raw数据。 - hmm configure
在HMMvoiceConfigure.java(line 356)里, 转到hts目录,通过configure,对编译选项进行设置。 生成对应的makefile。设置mgc order, gain 是否log, 各种生成文件名等。是否adapter。 - hmm voice feature selection
设置用于训练的hmm参数。