理论大部分内容来自统计学习方法1。谈谈自己粗浅的理解。
条件随机场应用场合:
- 在rnn等深度学习应用在nlp之前,几乎所有的nlp标注任务:分词,词性,命名实体识别的最好结果都是基于crf
- crf用于图像分割。realtime grabcut,五官分割等
- crf用于跟踪
- crf与rnn结合:CRFasRNN
1 概率无向图模型
概率无向图模型又称马尔可夫随机场,是一个可以用无向图表示的联合概率分布。
概率无向图的随机变量满足:成对马尔可夫性,局部马尔可夫性,全局马尔可夫性。
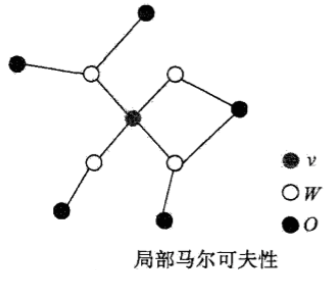
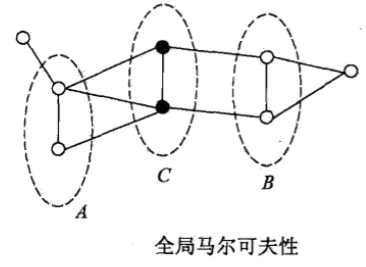
以上是概率无向图模型的定义,在实际计算时,通常使用因子分解将其转化为一系列概率的乘积。而,概率无向图模型的最大特点就是易于因子分解。
因子分解
团与最大团:无向图中任意有边连接的结点子集称为团(clique)。若该团无法加入新的结点,则成为最大团。

概率无向图的因子分解:将概率无线头图模型的联合概率分布表示为其最大团上的随机变量的函数的乘机形式的操作
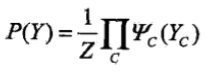
这里的函数一般称为势函数(potential function).通常是指数函数。
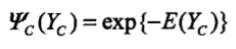
2 条件随机场
条件随机场是给定随机变量X的条件下,随机变量Y的马尔可夫随机场。学习P(Y|X), 预测时,给定输入序列x,求其概率最大的p(y|x)的输出序列y

一般的分词,词性任务只使用线性条件随机场,形式为:

在随机变量X取值为x的条件下,随机变量Y取值为y的条件概率形式:
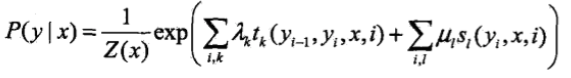
其中\(t_k\)和\(s_l\)是特征函数,\(\lambda_k\)和\(\mu_l\)是对应的权值。求和是在所有可能的输出序列上进行的。\(t_k\)是转移特征,依赖于前一个位置和当前位置。\(s_l\)是状态特征,依赖于当前位置。通常特征函数\(t_k\)和\(s_l\)定义为1或0,满足特征取1,不满足则取0. 条件随机场完全由特征函数\(t_k\),\(s_l\)和对应的权值\(\lambda_k\),\(\mu_l\)确定。
词性标注例子2

特征样例:

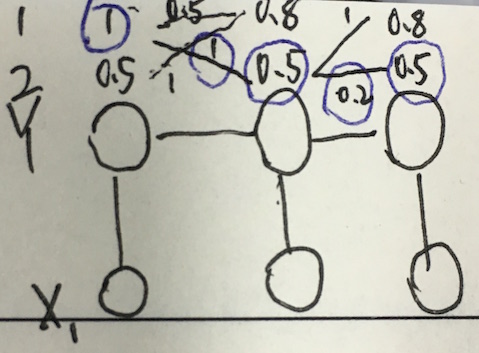
3 概率计算

计算如下:
4 crf在分词的应用
参考这篇博客
分词语料一般采用采用4-tag(B(Begin,词首), E(End,词尾), M(Middle,词中), S(Single,单字词))标记集. 例如:
人 们 常 说 生 活 是 一 部 教 科 书
B E S S B E S S S B M E
这样,被标记BE,BME的组成一个词:人们,生活, 教科书。其他的单独成词。 如果在分词那列的属性词上,标记的是词性,则,可以训练词性标注。
在分词任务中,文本是X,分词tag是要预测的Y。
工具包: CRF++: Yet Another CRF toolkit. 该工具包在example有日文分词样例。只要适配准备中文数据,并使用日文的特征模板即可训练。
数据集:bakeoff2005
特征模板
特征模板就是用来自动生成特征函数。
# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-2,0]/%x[-1,0]/%x[0,0]
U06:%x[-1,0]/%x[0,0]/%x[1,0]
U07:%x[0,0]/%x[1,0]/%x[2,0]
U08:%x[-1,0]/%x[0,0]
U09:%x[0,0]/%x[1,0]
# Bigram
B
流程:
训练: crf_learn -f 3 -c 4.0 template train.txt crf_model
测试: crf_test -m crf_model test.txt > predict.txt
生成评测数据: python crf_data_2_word.py predict.txt result.txt
评测: ./icwb2-data/scripts/score icwb2-data/gold/msr_training_words.utf8 icwb2-data/gold/msr_test_gold.utf8 result.txt > score
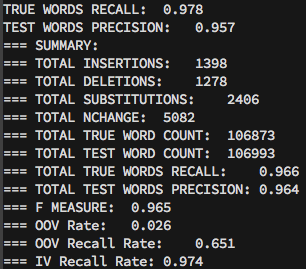
结果:
5 总结
- 从上面分词例子看来,nlp的很多任务实际上是数据问题。即使算法差不多,不同的数据会导致结果差别很大
- 依照上面的crf框架,应该可以用来对句子语调,停顿,轻重音预测