textrank基于pagerank算法,用于生成文本关键字和摘要。
Mihalcea R, Tarau P. TextRank: Bringing order into texts[C]. Association for Computational Linguistics, 2004
1. page rank
page rank 部分参考这篇博客
PageRank最开始用来计算网页的重要性。整个www可以看作一张有向图图,节点是网页。如果网页A存在到网页B的链接,那么有一条从网页A指向网页B的有向边。
构造完图后,使用下面的公式:
\[S(V_i)=(1-d)+d*\sum_{j\in{In(V_i)}}\frac{1}{\mid Out(V_j)\mid}S(V_j)\qquad(1)\]其中\(S(V_i)\)是网页\(i\)的重要性(\(PR\)值)。\(d\)是阻尼系数,\(1-d\)用于模拟用户随机点击某个网页的概率。\(In(V_i)\)是存在指向网页\(i\)的网页集合。\(Out(V_j)\)是网页\(j\)中的链接指向的链接集合。\(\mid Out(V_j)\mid\)是集合中元素的个数。
PageRank需要使用上面的公式多次迭代才能得到结果。初始时,可以设置每个网页的重要性为1。上面公式等号左边计算的结果是迭代后网页i的PR值,等号右边用到的PR值全是迭代前的。
举个例子:
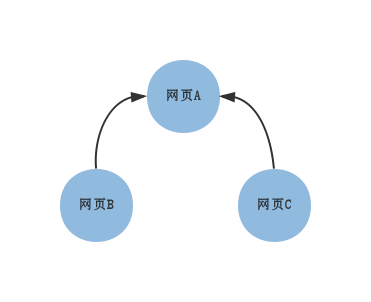
上图表示三张网页之间的连接关系。直觉上认为A最重要。根据连接关系可以得到下表:
| 结束\起始 | A | B | C |
| A | 0 | 1 | 1 |
| B | 0 | 0 | 0 |
| C | 0 | 0 | 0 |
横栏表示起始节点,纵栏表示结束的节点。在有向无权图中,若两个节点间有连接关系,对应值为1.
根据公式,需要对每一竖栏的归一化。
构造成矩阵M,使用matlab迭代100次求得最后每个网页的重要性:
M = [0 1 1
0 0 0
0 0 0];
PR = [1; 1 ; 1];
for iter = 1:100
PR = 0.15 + 0.85*M*PR;
disp(iter);
disp(PR);
end
运行结果:
98
0.4050
0.1500
0.1500
99
0.4050
0.1500
0.1500
100
0.4050
0.1500
0.1500
最终A的PR值为0.4050,B和C的PR值为0.1500。与直觉上认为A最重要相符合。
2. textrank
2.1 构图
在网页之间存在互相链接的关系。在文本分析中,我们采用的方法是将文本拆分成句子。然后一定长度\(k\)窗口扫描句子。 假设原始句子为:
\(w_1,w_2,w_3,w_4,w_5,…,w_n\)
加窗后为:
\([w_1,w_2,…w_k]\),\([w_2,w_3,…,w_{k+1}]\),\([w_3,w_4,…,w_{k+2}]\)…
在同一个窗口出现的单词间存在相互关系(边)。每个单词是一个节点,基于上面的构图,计算重要性。
2.2 加权
textrank的模型与pagerank相似。基本模型还是公式(1)。
在网页分析中,网页的相互应用不存在多个连接或者部分连接的情况。而在文本分析中,则可能存在节点间存在多条边的情形。这时候使用\(w_{ij}\)来表示两个节点\(v_i\)和\(v_j\)之间的连接强度。 \(WS(V_i)=(1-d)+d*\sum_{j\in{In(V_i)}}\frac{w_{ji}}{\sum_{v_k\in{Out(V_j)}}w_jk}WS(V_j)\qquad(2)\)
2.3 textrank流程

3. textrank 应用
3.1 关键词抽取
- 对文本进行分词。可以对某些词性的词进行筛选。
- 使用无权图。文本中在一定窗口内出现的两个词的节点直接标志为1.
- 在分词的过程中,可能会有部分词被分作多个词。比如,
支持向量机被分为:支持,向量,机。如果在构图时就考虑这些情况,会使得构图复杂度大大提升。解决方法是:通过一个后处理程序,将这些被误差的词重新组合起来。具体做法是:在候选关键词列表中,按照重要性降序排序,尝试组合这些词,如果组合的词在原文中出现次数超过一定次数(例如:支持,向量,机组成支持向量机),则认为应该是一个词。 - 作者同时测试了,使用有向图对结果没有帮助。
3.2 句子抽取(文本摘要)
文本摘要的任务就是抽取出最能概括文章内容的若干句子作为摘要。在文本摘要中,每个句子是一个节点。
句子间的关系通过表现为“结点间的相互推荐”。文本中的一个句子表达了若干个概念,相当于给读者对于表达了相同概念的句子一定的推荐度。这样,可以在这些相互推荐的句子间加上一条边。这个边的权值就是两个句子的相似度。
为了表示这种相似度,一般的做法用相同词语的个数来表示。为了避免长句子占便宜,会除以规范因子。
\[Similarity(S_i,S_j)=\frac{\mid\{w_k\mid w_k\in{S_i}\&w_k\in{S_j}\}\mid}{log(\mid S_i\mid)+log(\mid S_j\mid)}\qquad(3)\]这样,这个图就变成一个加权图了。使用公式(2)进行计算。