本文介绍neural style 进行风格传输。先介绍Gatys等人的原始论文,再介绍加速版本基于Perceptual Loss的风格传输。同时介绍另一种加速算法texture net。最后介绍该方法在语音传输上的应用。

原始neural style
原理

通过将用于物体识别的vgg网络不同层进行可视化,可以发现在输入图片之后,低层cnn保存更多的细节。高层cnn保留更多风格相关的内容。利用高层cnn输出基本上可以判别是什么东西,但是不保留所有像素特征。所以,在neural style中,使用高层cnn输出作为content。并且根据相关文献研究,用各层cnn输出可以构成特征空间用来表示style。使用gram矩阵表示各层cnn输出之间的关系。
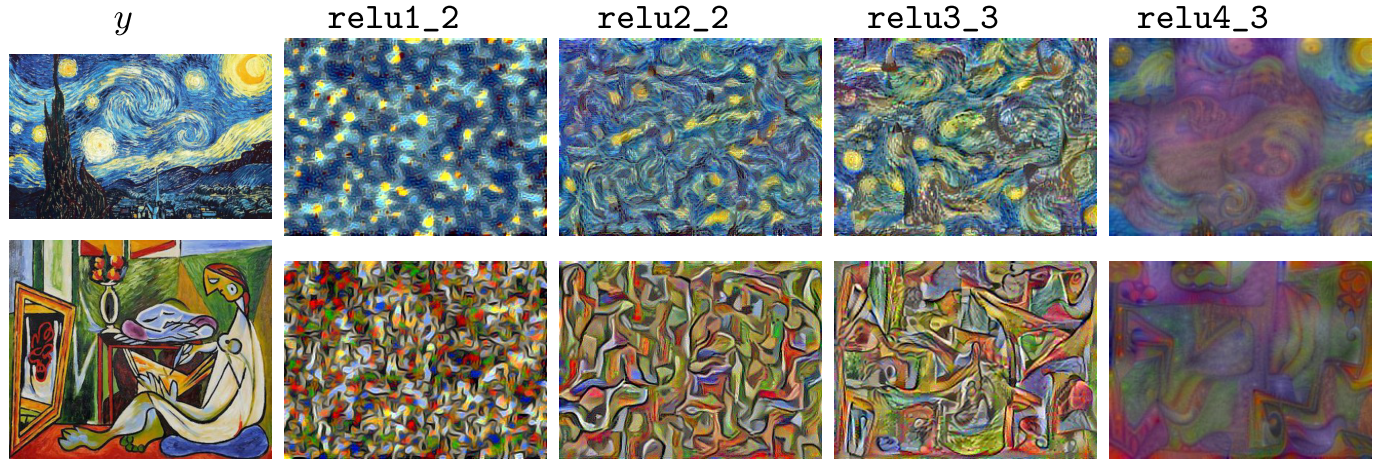
在实际应用中,content一般采用relu3_3(实际代码中也有采用relu3_1)特征。style采用‘relu1_2’, ‘relu2_2’, ‘relu3_3’, ‘relu4_3’
下图是更能说明问题:
对于content图片,将vgg各层输出重建图像的结果:

对于风格图片,各层输出重建结果:
整体流程:
- 将输入图片(content)扔到网络中,计算content_cnn。
- 将style输入到cnn中得到各层style_cnn, 再计算各层style_cnn的gram矩阵:style_gram
- 将当前迭代的图片current_image输入到cnn(在第一次迭代中,该图片由高斯白噪声随机初始化)。获取content cnn输出记为image_content_cnn, 输入style 中获得image_style_cnn并计算gram矩阵image_gram。 以(content_cnn - image_content_cnn)^2 + (style_gram-image_gram)^2作为loss。反向传播
修改vgg各层网络参数,并修改current_image - 重复以上步骤
算法


其中G是style_cnn的gram矩阵。ps : gram矩阵的计算见后文。

上述算法出现之后,艺术化风格吸引了大量的关注。但是由于生成一张图片大约需要一分钟左右时间,所以很难实用。下面介绍另外一个算法,使得艺术化风格可以实时。
Perceptual Loss neural style
原始的neural style之所以慢,是因为需要在风格传输的时候,学习网络参数。很多研究者就想,是否可以学习一个网络使得原始图片可以直接转化为目标图片。而这个网络的学习则由另一个网络来判断好坏。这其实是GAN的思想。mxnet的作者之一也是GAN的作者很早就提出这个想法,并实验了该方案,参考这篇文章。Perceptual Loss neural style思想与其类似。下面介绍Perceptual Loss neural style。
ps: 知乎评论@罗若天评论这个不是GAN。后文也将介绍texture net。按照这个说法,texture net合成texture是生成模型,但是进行style传输,需要一张content图片,也不叫生成模型?生成模型,判别式模型待考证。
Perceptual loss是encoder decoder模型,和gan有点距离,因为gan的输入有一个随机向量,而encoder decoder的输入没有。更像gan的有另外一篇做style的paper,texturenet。 其次,生成模型不是一个严谨的说法。generative model指的是对p(x, y)进行建模。讲道理perceptual loss这个模型更像是判别模型。
原理

训练:
在上图中,输入图片通过一个网络transform net转化为目标图片$\hat{y}$。并将这张图片输入到loss network中,获取feat层输出$y_c$,style层输出$y_s$。这个目标图片输入到loss network中,获得style输出和feat输出。这两个输出与原始图片在网络中的输出对比,构造loss,反向传播优化transform net,loss network保持不变。
使用mscoco数据集,对于每种风格训练一个transform net。并将transform network的参数保存下来。有了这样的训练过程,可以保证对于大多数输入图片的对应风格输出都较好。transform network学习的其实就是neural network loss的最小化参数。
生成:
在生成的时候,只要扔到网络中,输出的就是目标图片。不需要优化过程,所以速度很快。
在transform network的网络结构中,还加入了down sample 和up sample层。download sample的cnn stride为2,up sample的stride为0.5。通过这两层图片大小保持不变,但是得到两个好处:1. 计算效率更高;2. 可以观察到更大的范围。
细节
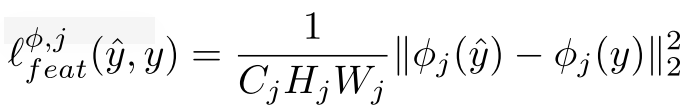

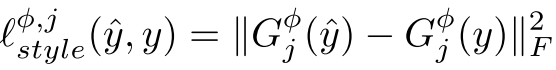
gram 矩阵意义: 在第l层cnn输出$c*h*w$的feature map。 也就是在$h*w$的网格上,每个点都有$c$维特征。gram矩阵$c*c$, 就是这c维特征的非中心化协方差。gram矩阵同时保证了输入图片shape和style shape无关。
![]()
texture net
纹理合成就是给定一块纹理,使其生成更大的符合该图片纹理结构的图片。如下图所示,左边是原始图片,对齐采样,生成右边的纹理图片。如果图片合成让人看不出来,则说明纹理合成效果很好。
将cnn用于纹理合成最初也是由Gatys等人提出的。这篇文章发表在其neural style之前,是neural style的初期版本。网络结构与neural style一样,只是不是用于风格传输,所以不需要content loss。

Dmitry Ulyanov等人提出texture net,既可以用于快速纹理合成,也可以用于fast neural style风格传输。下面介绍论文细节。
原理

上图是texturenet的网络结构图。左边是生成网络,右边是判别网络。判别网络采用的是与neural style论文相同的vgg网络。在计算完损失函数之后,与Perceptual Loss neural style一样,不更新vgg网络参数。
texture synthesis任务和style transfer 任务的输入和损失函数不同。
texture synthesis:
高斯噪声图片输入左边的生成网络生成texture, 右边的判别网络计算gram loss,并更新左边的网络参数。训练完毕之后即可输出texture synthesis结果。没有离线预先训练模型,所以对于生成图片没有加速作用。
style transfer:
高斯噪声图片和content image输入左边的生成网络生成style image,右边的判别网络计算gram loss和content loss,再更新左边的网络参数。与Perceptual Loss neural style的transform network一样,可以现在一个数据集上预训练某个style的网络参数并保存,在真实style合成的时候,只要一个前向过程就可以得到style image。
细节
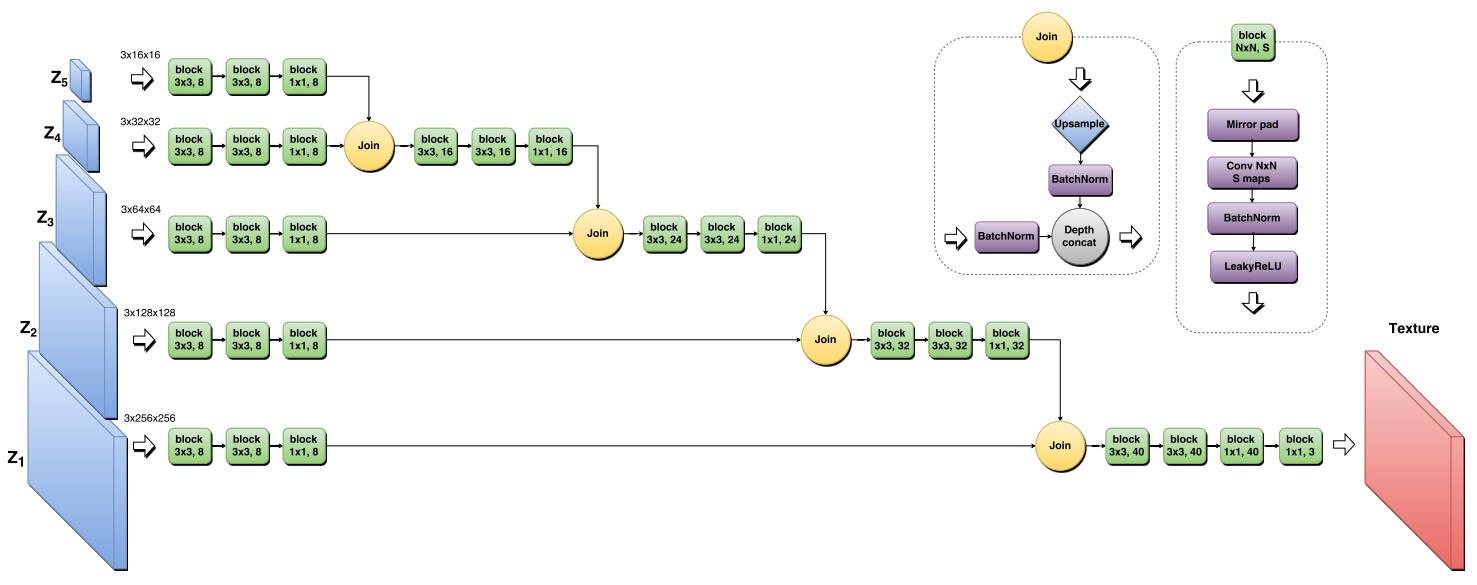
在texture synthesis任务中,输入Z是各个尺度的噪声图片。
在style transfer任务中,输入是各个尺度噪声图片和各个尺度content image的concat。
neural style audio
参考这篇文章, tensorflow代码。
思考
- 这个代码中的style transfer without color是怎么实现的?
- 生成模型,判别式模型?
参考
- A Neural Algorithm of Artistic Style
- Perceptual Losses for Real-Time Style Transfer and Super-Resolution
- end2end mxnet
- mxnet perceptual loss
- mxnet neural style
- deep 2min demo in zhihu
- Texture Synthesis Using Convolutional Neural Networks
- Texture Networks: Feed-forward Synthesis of Textures and Stylized Images