本文介绍depthwise separable convolution。我们知道在进行卷积操作的时候,卷积核的维度是: (kernel_size, kernel_size, input_channel, output_channel),也就是说同时进行通道间和空间(通道内)的计算。实验证明,这两部分是可以分开的,可以分解成独立的两个部分: 通道间计算,空间计算。文章探索的网络结构是在inception v3上进行的,在参数数量不变的情况下,在imagenet等多个大数据集上超过inception v31。
separable convolution将正常卷积分解。在tensorflow,keras等框架中,将分解后的操作称为:
- depthwise convolution。在单个通道内的卷积操作。卷积核大小一般是3x3
- pointwise convolution。通道间的操作。卷积核大小是1x1
本文对inception v3的修改主要是对其中的Inception modules替换成depthwise separable convolution。修改后的模型称为xception2.
接下来我们先来看一下是怎么做的修改。
结构演变
inception module原始结构

将各种分支简化成相同的模式:
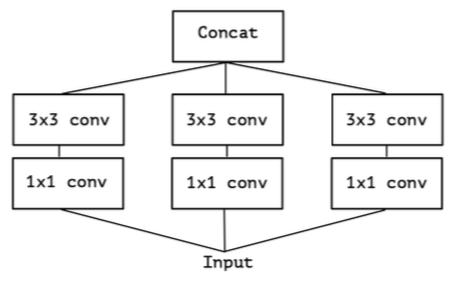
1x1卷积实际上可以进行合并操作, 只要分group即可:
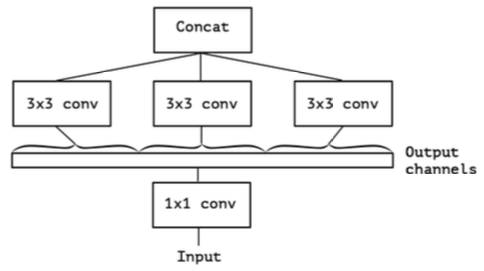
在极端(extreme)情况下,每个group只有一个通道:
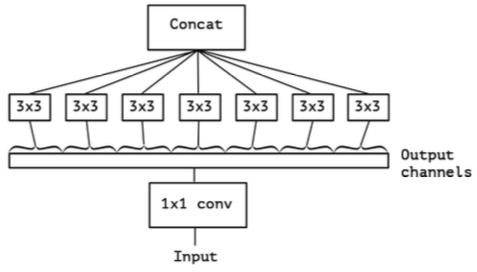
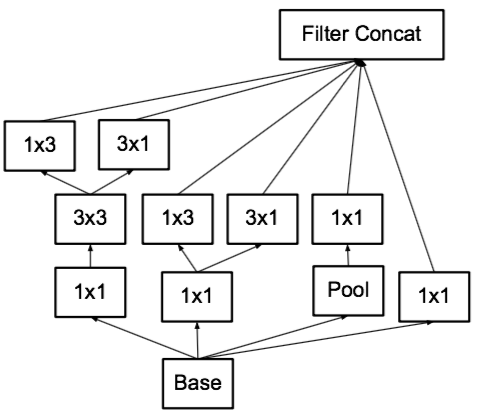
3x3的卷积核一般称为
xception与inception差异
在实际使用中,xception和inception module有以下不同之处:
- 顺序不一样。inception先1x1再3x3。xception采用的depthwise separable convolution是先3x3再1x1
- 激活方式不一样。inception一般使用在每个卷积操作后加入relu。xception则不加。
对于第一个不同,一般认为这是不重要。主要是因为这些网络结构都会堆叠很多层,所以顺序不同并不会有什么影响。对于第二个不同,对结果是有影响的。作者通过实验表明,没有用激活函数,效果更好。
整体结构

下面附上inception v3结构作为对比。
inception v3结构
整体结构:
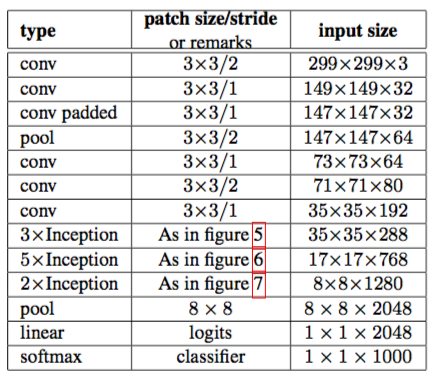
figure5:
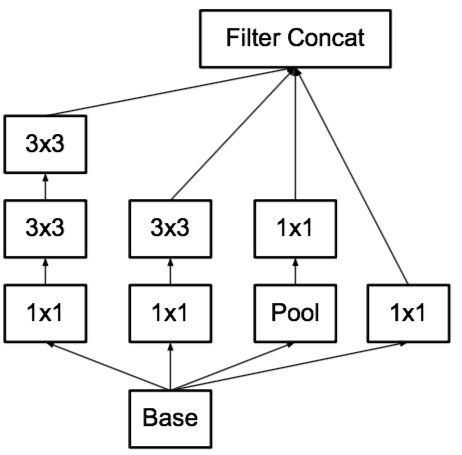
figure6:
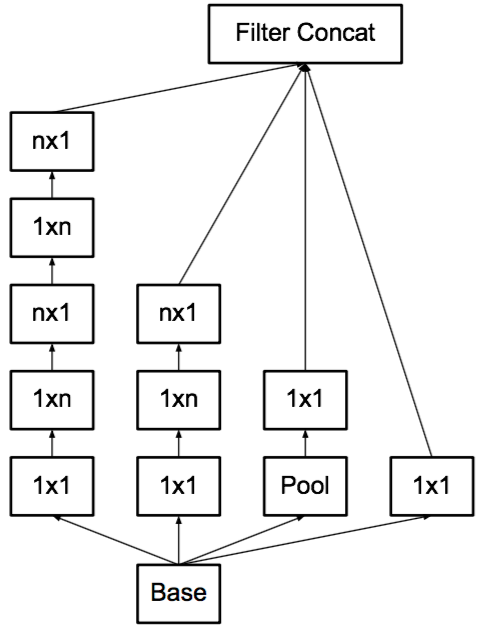
figure7:
参考文献: