- seq2seq
- attention
- monotonic attention
- gated linear unit
- conv seq2seq
- highway network
- causal
- softsign
- 参考文献
最近打算用mxnet复现tacotron1,deepvoice32,wavenet3等论文。后面会写一系列文章记录相关论文细节,以及复现过程中遇到的问题。本文先介绍所需要的预备知识,扫清大家阅读后面文章可能碰到的障碍。
关键知识主要包含:
- seq2seq, encoder,decoder 4
- attention5
- monotonic attention6
- gated linear unit 7
- conv seq2seq 8
- highway network 9
- causal
- softsign
seq2seq
seq2seq论文4发表于2014年,目前已经有3000多引用。
seq2seq用来做序列学习非常有效。比如聊天系统,语音识别,ocr,机器翻译。这些应用最显著的特点就是: 输入输出不一样长,没有一一对应关系。现在我们来举个例子:
假设现在有一个翻译任务是想从一个序列(good, morning) 学习到(早, 上, 好)。传统的dnn没办法直接操作。而seq2seq可以。下面开始介绍seq2seq具体细节。同时,我们把输入抽象为: (A, B, C), 输出抽象成(X, Y, Z).
看一下下面这张图就知道seq2seq是怎么工作的了。
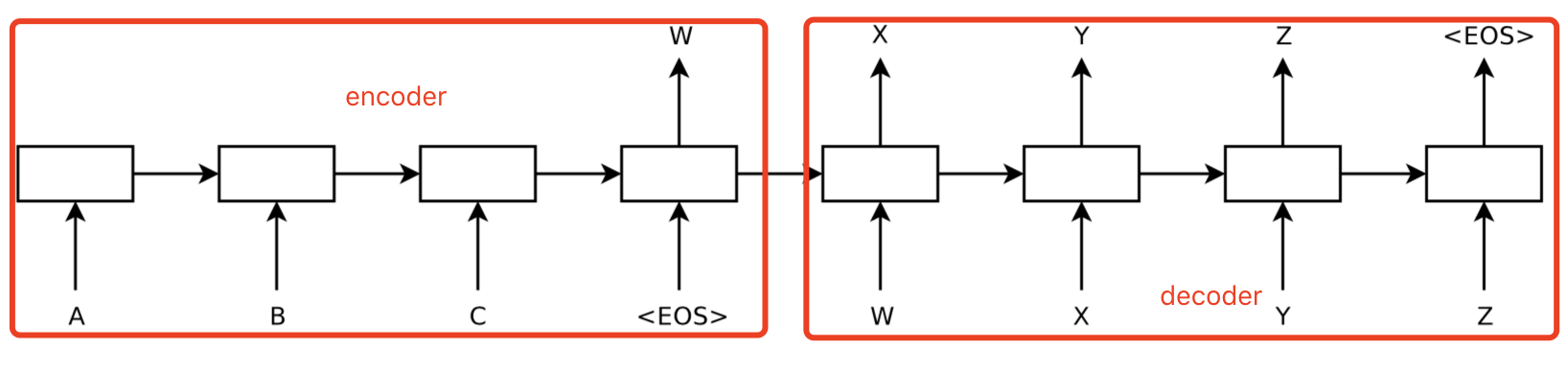
seq2seq分别encoder和decoder。上图中,左边是encoder,右边是decoder。左边是一个RNN,将输入(A,B,C)输入到网络中,获取固定长度的隐藏向量W。也就是整个(A,B,C)序列被编码成固定长度的向量W。右边是decoder,也是RNN。由W出发,获取输出X,再把X作为输入,获得Y…一直持续下去,直到碰到结束符为止。最后,decoder输出的(X,Y,Z)就是序列预测的结果。
现在我们来思考一个问题。decoder输出的到底是什么?凭什么能对应到任务所需要的所要映射的序列呢?又是怎么知道是否应该结束呢。
- 翻译任务: 输出是具体的词。有个词表,其中包含了结束符。decoder对每个输出做softmax,即可知道到底是哪个词了。但实际解码没有这么简单。考虑到softmax可能有几个词概率差不多的。那么是否应该用这几个词作为输入,继续解码,看看谁的后续概率更高就选谁的。答案是: YES。用这种方式的解码就是我们常说的束搜索。也就是beam search。
- 语音合成任务: 输入是文本,输出是频谱特征。输入的处理方式与其他任务没有区别。输出的频谱特征是一堆连续值,不是分类任务,怎么知道是否结束呢?答案是:
- 设置一个最大解码次数,达到了自然停止。最后对合成语音进行端点检测,去掉尾部多余的空音。
- 设置一个阈值,例如0.2. 如果输出的所有值都这个数字, 就结束。
todo:待确定。碰到句子中间的空音怎么办?空音的频谱不是0?
attention
deepvoice系列,tacotron这些end2end语音合成论文充斥着大量的attention字眼,如果不懂这个,看起来可能会哭。
attention5 这篇论文提出于2015,目前引用已经将近3000了。相当厉害。attention有很多变种,可以用于seq2seq,也可以不用。最初的论文是用于提升seq2seq的效果,我们就以这个为例。后面的一些扩展大家自己看。
动机
seq2seq是将输入通过encoder映射到一个固定向量,然后从这固定向量出发获得解码输出。但这实际上有点违反人类的认知的。比如上面的例子: (good, morning) 翻译到(早,上,好)。“早上“与”morning“有关系,与”good“几乎没有关系。”好“与”good“有关系,与”moring“几乎没有关系。
attention论文认为,简单的将整个输入映射到一个固定向量是不合理的。应该在解码的时候,寻找与其有关系的输入。然后有这些输入一起决定应该输出什么。这就是attention
细节
要加一些公式了,莫慌,都很简单。
输入: $\mathbf x=(x_1,…,x_{T_x})$
输出: $\mathbf{y}=(y_1,…,y_{T_y})$
seq2seq的encoder一般是RNN。在每个时刻, rnn隐藏层输出$h_t$ 表示为($f,q$表示某些非线性表达式):
\[h_t=f(x_t,h_{t-1})\]最终,用隐藏层输出将输入编码成固定长度的向量$c$
\[c=q({h_1,…,h_{T_x}})\]在seq2seq中,一般只取最后一个隐藏层的输出作为编码向量$q({h_1,…,h_{T_x}})=h_{T_x}$
在attention中,${h_1,…,h_{T_x}}$都会派上用场,而不是只用最后一个。简单来说,attention就是在预测某个decoder输出的时候,不再是固定的$h_{T_x}$, 而是$h_1,…,h_{T_x}$ 的加权和。那么,应该权重应该是多少呢?我们一步步来讲。
在$i$时刻预测$y$输出:
\[p(y_i \mid y_1,…y_{i-1}, \mathbf x)=g(y_{i-1}, s_i, c_i)\]其中,$s_i$ 是上一时刻rnn隐含层的输出。$g$是decoder rnn。关键就是$c_i$怎么来的。
\[c_i=\sum_{j=1}^{T_x}\alpha_{ij}h_j\]也就是加权组合。那么权重 $\alpha$ 怎么来的:
\[\alpha_{ij}=\frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})}\]注意上式的形式,其实这就是softmax attention。其中,$e_{ij}=a(s_{i-1}, h_j)$
$a$是对齐模型。表示输入$j$ 与输出$i$的匹配程度。通常也是由神经网络来学习。
直观来说,$\alpha_{ij}$或者$e_{ij}$表示上一时刻隐含层输出$s_{i-1}$与$h_j$对于这时刻隐含层输出$s_i$ 和解码输出$y_i$的重要程度。
在实际的网络图中,一般用query表示$s_{i-1}$, key表示下$h_1,…,h_{T_x}$. value表示通过key或者key通过另外一些网络层的隐藏层输出。下面这张图可以形象的表示attention的过程.
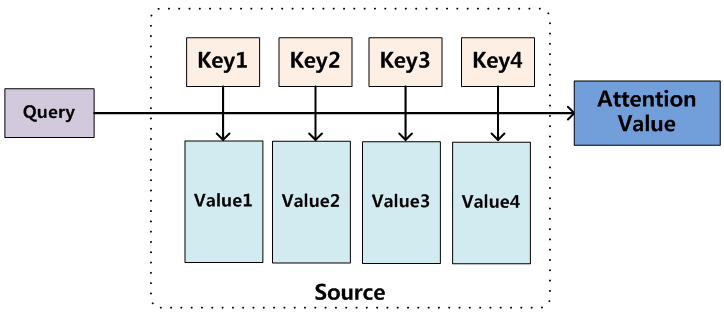
中间部分是encoder。输入4个时刻的隐藏层$(h_1,h_2,h_3,h_4)$分别表示为(key1,key2,key3,key4), 分别对应的value是(value1, value2, value3, value4). query是$s_{i-1}$. 通过query和key计算相似度,这些归一化的相似度对value进行加权求和,最后获得attention value
attention的形式有很多种。可以是encoder和decoder之间算相似度。也可以分别在encoder和decoder内部计算相似度(self attention)。谷歌的attention is all you need就是堆叠了大量的self attention。
alignment
怎么知道训练是否有效,一般会将学习到的对齐用图像画出来。比如:

怎么理解呢? 对于翻译任务,输入和输出一般都是呈线性关系的。正常来说,输入序列先出现的词,在输出中,其对应的词也会先出现。上面这张图表示输入输出的响应强度。因为时序性与局部性,一般来说,对齐图上,对角线会比较亮,一般来说,这表明学习基本没有问题。反之,如果这张图很混乱,那么就表明学习是无效的。
ps: 张俊林发表在程序员上的一篇文章讲解很通俗易懂。上面内容如果看不懂,建议花点时间看看这篇文章。
monotonic attention
一般的attention需要对每个query计算跟整个key的相似度。复杂度是二次的。而且无法应用于实时语音识别这种online应用。monotonic attention6这篇论文提出了单调性,也就是在上面在alignment中,我们提到了时序性和局部性。也就是,不再对整个输入序列的计算softmax,而是对上一次最后一个attention位置外后几个timestep的窗口范围内计算softmax。通过实验表明,monotonic attention比softmax attention只有很微小的性能损失。这篇论文进行了大量的理论分析,有兴趣的可以看一下。
gated linear unit
之前的基于神经网络的语言模型一般是用rnn。rnn可以获得长时依赖,所以效果会比较好。但是rnn存在效率问题,而cnn 可以并行。Language Modeling with Gated Convolutional Networks7这篇文章通过堆叠多层cnn来获取比较的感受野, 同时作者通过gated linear unit来提高性能,最后效果能与rnn相匹敌。
直接看一张图:
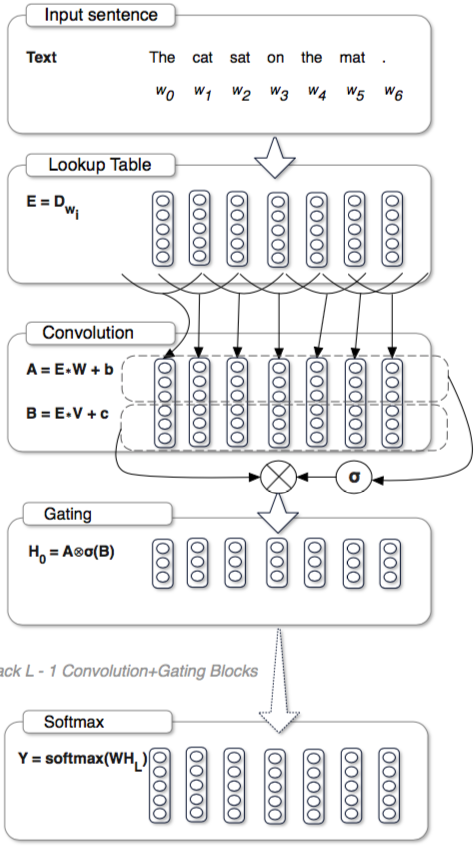
上图中,输入经过embeding(获得词向量),然后分别分别输入两个卷积层A,B,对卷积B的结果取sigmoid($\sigma$),再与A对位相乘($\otimes$),获得H。
其中:$H=A \otimes \sigma(B) $,门$\sigma (B)$控制附近的哪些A是有效的(相关的)。
conv seq2seq
deepvoice3第一句就是:
We present Deep Voice 3, a fully-convolutional attention-based neural text- to-speech (TTS) system.
但是明明有全连接层啊。怎么还说自己全卷积。怎么回事?
其实这里的fully-convolutional描述的是seq2seq的方式。
我们正常听到seq2seq,立马就想到用rnn。facebook的这篇论文[^conv_s2s]用fully-convolution实现了seq2seq。效果不比rnn的差。优势是大大提升了训练速度。
谷歌对标conv seq2seq,推出了Attention is all you need10这篇论文,不用rnn,cnn。堆积大量的self attention,用来计算上一层到下一层的映射。这是后话了。
我们先看一下conv seq2seq的整体结构。
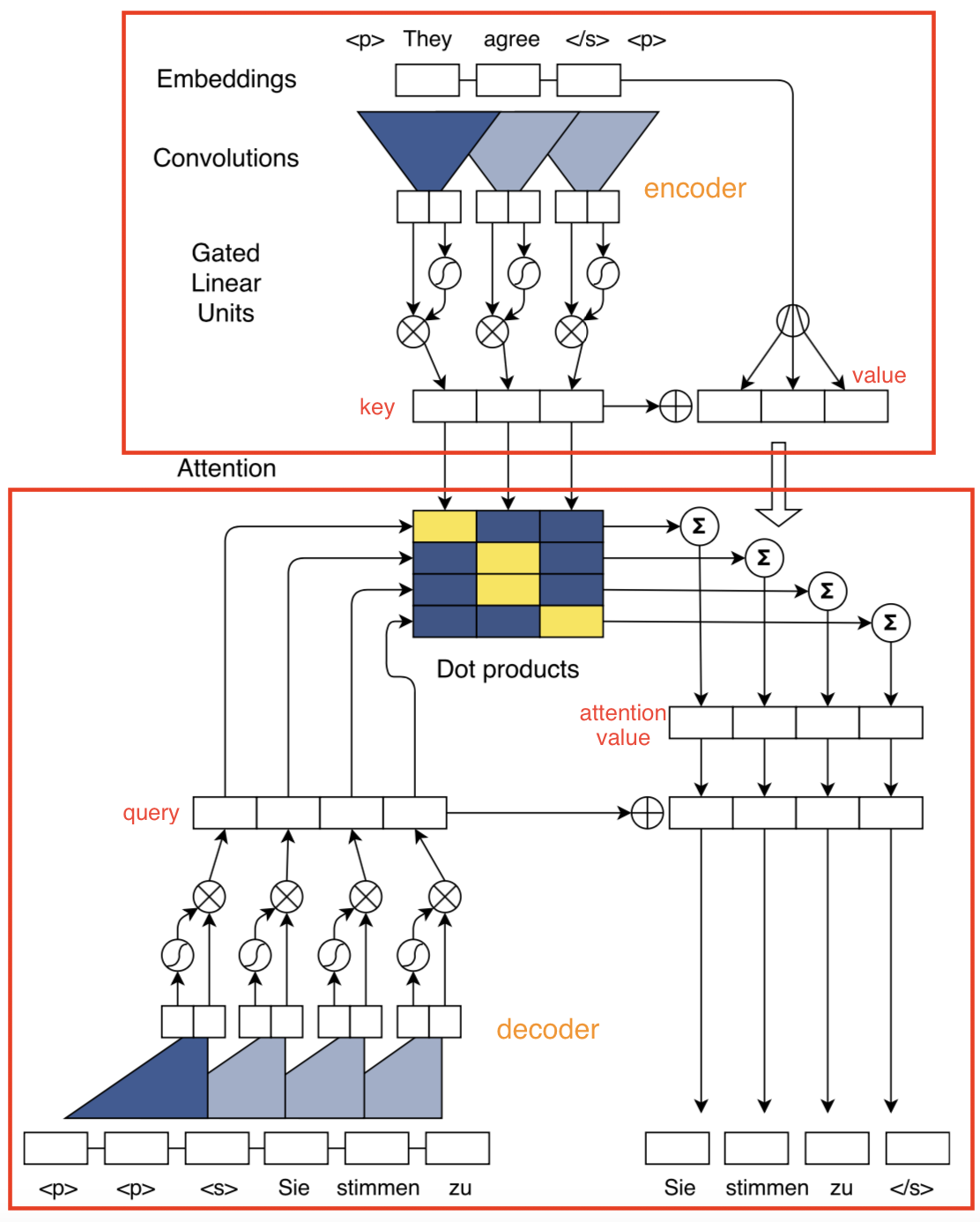
上图中,encoder通过cnn和gated linear units对输入进行编码。变成key,value。decoder使用同样的方式,将输出变成query。通过attention机制获得attention value。再加上原始的query,一起预测输出。
在训练阶段,由于输出的所有词都是知道的,而且cnn没有状态,所以decoder整个都是可以并行的,不需要先一个个一次进行decode。这也就conv seq2seq比rnn训练速度快的奥秘。而在预测阶段就无法并行了,所以速度不会明显的提升。
好了,整体结构就是这样。可能我们心中会有疑问:cnn没有历史状态,凭什么跟rnn比?
position embeddings。这是这篇论文首创。后面很多用cnn做conv seq2seq的文章都会用到这个。只是具体的方式不大一样。本文通过引入position embeddings对文本位置进行编码。简单的说,就是在每个词的向量加上该词在句中的绝对位置作为后续输入。
卷积block。堆积多层cnn,这样可以获得更大的感知野。并使用gated linear units
多步 attention。下一层的attention是上一层attention value的加权平均。
归一化策略。为了训练的稳定性,对网络的某些部分进行缩放。
- 对residual block的输出和attention进行缩放。
- 对input与residual block的输出之和乘上$\sqrt 5$。
- 对condition input $c_i$乘上$m\sqrt {\frac{1}{m}}$
- 对encoder层的梯度除以attention数目
网络初始化。这篇论文还提出了新的权重初始化。todo:待完善.
highway network
大量的研究表明,增加网络层数可以提升效果。但是深度增大也意味着训练难度的增加。highway network9这篇论文提出一直方式来降低训练难度。这种方式可以使得信息直接穿越几层传导到后面的网络层,所以称为highway network。
假设我们正常的网络层:
\[y=H(x,W_H)\]highway network增加了两个门。
\[y=H(x,W_h)\cdot T(x, W_T)+x \cdot C(x,W_C)\]$T(x, W_T)$, $C(x,W_C)$分别被称为transform门和carry门。分别表示对原始信息信息转换的程度和保留程度。在实际中,一般取$C=1-T$。
所以上式变成:
\[y=H(x,W_h)\cdot T(x, W_T)+x \cdot (1-T(x, W_T))\]pytorch源码如下:
class Highway(nn.Module):
def __init__(self, in_size, out_size):
super(Highway, self).__init__()
self.H = nn.Linear(in_size, out_size)
self.H.bias.data.zero_()
self.T = nn.Linear(in_size, out_size)
self.T.bias.data.fill_(-1)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
H = self.relu(self.H(inputs))
T = self.sigmoid(self.T(inputs))
return H * T + inputs * (1.0 - T)
causal
causal convolution的意思就是,卷积的输出不依赖于未来的输入。这在自回归(autoregressive)模型是必要的。因为只能根据前面的结果预测当前的值。
non-causal convolution就是普通的卷积。
softsign
deepvoice3这篇论文用到了softsign。
softsign其实就是与tanh类似的一种激活函数。表达式是:
\[f(x)=\frac{x}{\lvert x\rvert +1}\]激活图如下:
参考文献
-
Y. Wang, R. Skerry-Ryan, D. Stanton, Y. Wu, R. J. Weiss,N. Jaitly, Z. Yang, Y. Xiao, Z. Chen, S. Bengio, Q. Le,Y. Agiomyrgiannakis, R. Clark, and R. A. Saurous, “Tacotron:Towards end-to-end speech synthesis,” in Proceedings of Inter-speech, Aug. 2017. ↩
-
W.Ping,K.Peng,A.Gibiansky,S.O ̈.Arik,A.Kannan, S. Narang, J. Raiman, and J. Miller, “Deep voice 3: 2000- speaker neural text-to-speech,” CoRR, vol. abs/1710.07654, 2017. ↩
-
Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. WaveNet: A generative model for raw audio. arXiv:1609.03499, 2016 ↩
-
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks. In Advances in neural information processing systems, pp. 3104–3112, 2014. ↩ ↩2
-
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In ICLR, 2015 ↩ ↩2
-
Colin Raffel, Thang Luong, Peter J Liu, Ron J Weiss, and Douglas Eck. Online and linear-time attention by enforcing monotonic alignments. In ICML, 2017. ↩ ↩2
-
Yann Dauphin, Angela Fan, Michael Auli, and David Grangier. Language modeling with gated convolutional networks. In ICML, 2017. ↩ ↩2
-
Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann Dauphin. Convolutional sequence to sequence learning. In ICML, 2017. ↩
-
RupeshKumarSrivastava,KlausGreff,andJu ̈rgenSchmidhuber.Highwaynetworks.arXivpreprint arXiv:1505.00387, 2015. ↩ ↩2
-
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. arXiv:1706.03762, 2017. ↩