本文介绍light head rcnn1。face++出品。小网络在coco取得30.7mAP,102 fps。速度和准确性都超过了ssd,yolo v2。论文网络基于rfcn,实验详实, 每一步都列出了所做的改变对结果的效果(update:更像是试出一个不错的网络结构,然后做补充实验)。本文之所以快,是因为light head,具体来说,就是使用一个channel数目比较小(thin)的feature map, 并且使用只有pooling层和单层全连接层的rcnn子网络。那么怎么能做到又快又小?
首先:论文说的head,指的是网络的高层。而不是基础网络。
背景
我们先来看一下本文网络结构和faster rcnn,rfcn的对比。
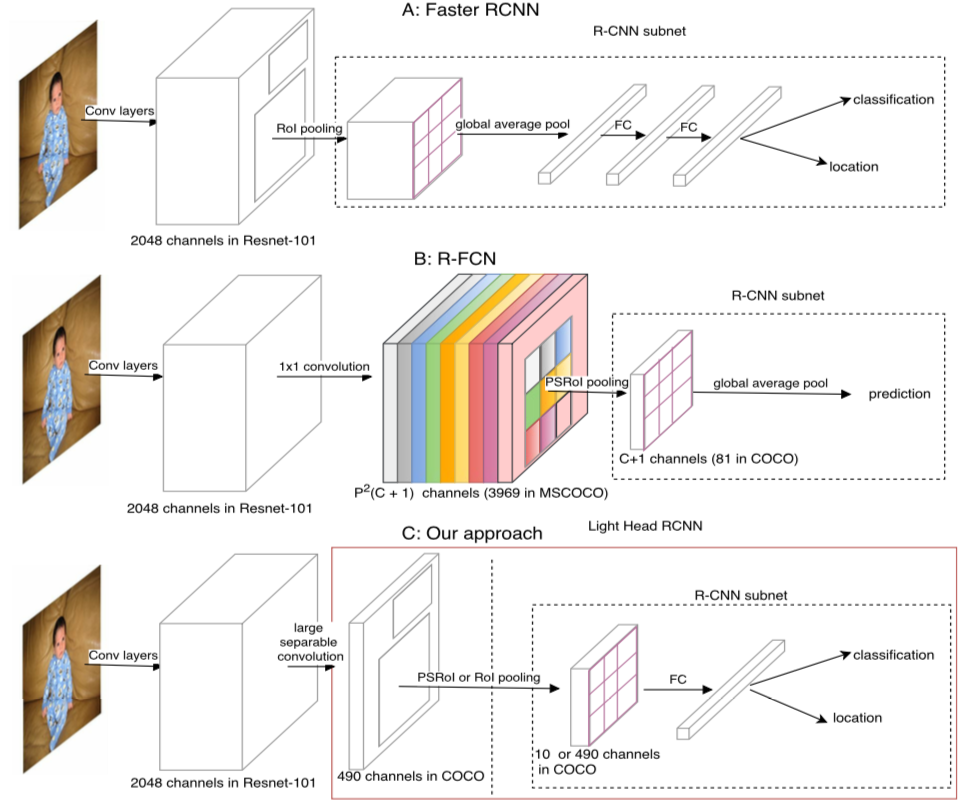
faster rcnn之所以慢是因为对于每个roi之后的计算比较复杂,而roi数目又比较多。rfcn虽然在对roi的计算几乎是cost free的(只要一个vote操作),但是需要计算一个很大的score map $k\times k\times (C+1)$。计算这个score map使得rfcn速度并不理想。light head rcnn这篇文章计算一个小的feature map,大小通常是 $k\times k\times 10$,大大的提高了效率。
从准确的角度来看,faster rcnn在第一个池化层之前采用全局均值池化来减少计算量。这其实会对定位有不利影响(此话怎讲,faster rcnn并无全局均值池化?难道是实际应用中经常会这么做?)。而rfcn在计算score map之后只是做一个池化操作,准确度一般来说比不上那些有对具体roi进行计算的网络。针对以上缺点,本文设计的网络只采用单层全连接作为rcnn subnet。同时,使用thin feature map来提高计算效率。
light head rcnn
一句话: light head rcnn就是讲rfcn的pspooling层之前的channel数减少,然后发现无法映射到对应类别,于是再加上一个全连接层

上图是在rfcn上修改成light head rcnn。
thin feature map
如第一张图所示,在coco上训练,如果k取值为7,那么feature map大小是490. 远远小于rfcn的7x7x81。由于通道数目小,也就避免了有害的全局均值池化。关键是,采用thin feature map会不会使结果变差呢?
我们先来考虑一下,现在神经网络中为什么最常用的是3x3卷积核。因为在kernel很多的情况下可以节省计算量。而现在既然通道数很小,那么采用更大的卷积核也就没有什么问题了。
基于以上事实,论文采取如下结构的large separable convolution:

论文并没有进行对比试验来表明,在修改后的结构中,采用这个large separable convolution是否有提高。这也是为啥我觉得实验不充分的地方。
rcnn subnet
由于通道数少,后面增加全连接层也就没啥压力了。有了全连接层,结果相对于rfcn会有一些优势。
rpn
当然,作为检测器,还需要rpn。文章用到的rpn与faster rcnn的不同之处在于: faster rcnn的anchors采用scales: $128^2, 256^2, 512^2$, 而本文采用的是: $32^2, 64^2, 128^2, 256^2, 512^2$
其他细节
- 用mask rcnn的RoiAlign可以提高mAP
- 大网络用resnet101可以在coco上超过其他所有two stage的网络。小网络用xception并把其中bottleneck结构的卷积层替换成channel wise卷积,在保证足够精度的情况下,速度远超ssd,yolo。
- 大小网络上的k取值,$C_{mid}$, $C_{out}$取值不一样
结果
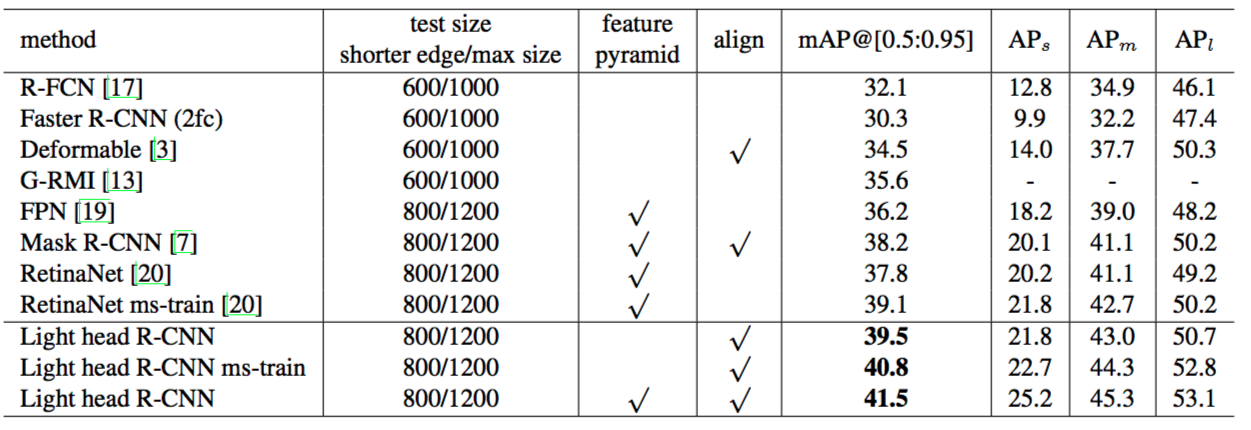
大模型在准确度上碾压对手:
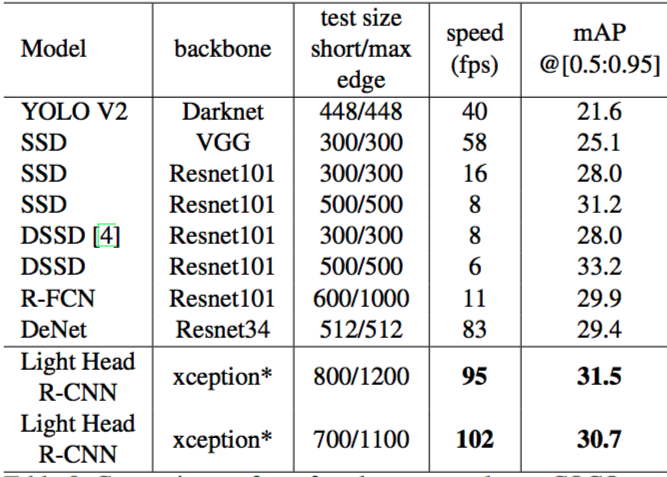
小模型在速度上碾压对手:
源码
这里有个mxnet实现。看了一下应该理解无误。todo:修改一下这个网络使用不同的backbone network。测试在xception上是否真的有这么高的速度和准确性。
参考文献
-
Light-Head R-CNN: In Defense of Two-Stage Object Detector ↩