本介绍iccv17最佳学生论文focal loss1。一般来说,在物体检测中,one stage速度比较快,但准确度比较低。本文提出导致这个问题的原因是:前景背景样本极度不均衡(准确来说,应该是存在大量easy负样本)。focal loss介绍一种新的损失函数来降低已经被正确分类样本的权重。本文提出一个one stage网络retinanet, 使用focal loss进行训练,使得最终效果与one stage一致,同时效果超过two stage。
本文对原理讲解很好,模型初始化技术也值得学习。
背景
我们知道传统的物体检测一般使用滑动窗口+hog特征+svm分类的方式来进行。最好的物体检测一般是基于dpm的变种。而将深度学习引入到物体检测后,取得很好的效果。一般分为两种类别。
- two stage: 用rpn先预测候选位置,再对候选位置进行分类已经预测偏移。以faster rcnn为代表。
- one stage: 使用一个网络直接预测物体的位置和类别。以ssd,yolo为代表。
一般来说,one stage速度快但准确度较低。本文提出,导致这个问题的原因是: 正负样本的极度不均匀导致的。那么让我们思考一下,为啥two stage没有这个问题呢?
one stage和two stage的区别
先让我们回忆一下,two stage是怎么做的:
- 使用rpn筛选2k个候选区域。这些候选区域一般都非常像前景。
- 采样策略。在第二阶段训练的时候,会控制正负样本比例是1:3或者OHEM(online hard example mining)
通过以上策略,two stage可以比较好的控制正负样本不均衡。
而one stage呢?one stage是直接给出坐标以及分类概率。相当于说,对每个坐标都进行分类。而这些坐标是连续的,存在无数的框…(也就是dense)。存在大量的背景。用这种样本训练,会使得hard example被淹没。最后学习到一个退化的模型。
针对这个问题,本文提出focal loss来解决。
focal loss
我们先回顾一下交叉熵的损失函数是什么样子的。(对交叉熵推导不熟悉的,参考这篇博客) \(CE(p, y) = \begin{cases} -log(p) & \text{if $y=1$ } \\ -log(1-p) & \text{otherwise.} \end{cases}\)
其中 $y \in {\pm 1}$. 分别是正负样本的标签。$p\in [0, 1]$表示模型对正样本$y=1$的预测概率。为了方便,后面用$p_t$表示。定义如下: \(p_t = \begin{cases} p & \text{if $y=1$ } \\ 1-p & \text{otherwise.} \end{cases}\)
现在想让我们思考一个问题,这个$p_t$有什么数值特性?
我们这样考虑。
- 如果现在正样本,$p$越大,表示预测越准。在数值上的表现为$p_t$越大。
- 如果是负样本, $p$越小,表明预测越准。在数值上同样表现为$p_t$越大。
所以$p_t$可以表明一个预测的准确程度。也就是分类的难易程度。这个值越大,说明分类对了概率高,也就是分类难度低。
这样交叉熵就可以重写成: $CE(p,y)=CE(p_t)=-log(p_t)$
为了解决类标签问题,在交叉熵损失函数里一般还会加上$\alpha$来作为平衡因子。$CE(p_t)=-\alpha log(p_t)$。这个$\alpha$的取值一般是通过正负样本比例或者交叉验证得到的。
这里对交叉熵增加$\alpha$只能控制正负样本的比例。不能解决大量简单负样本的问题。focal loss想要对简单样本进行降权,具体形式如下:
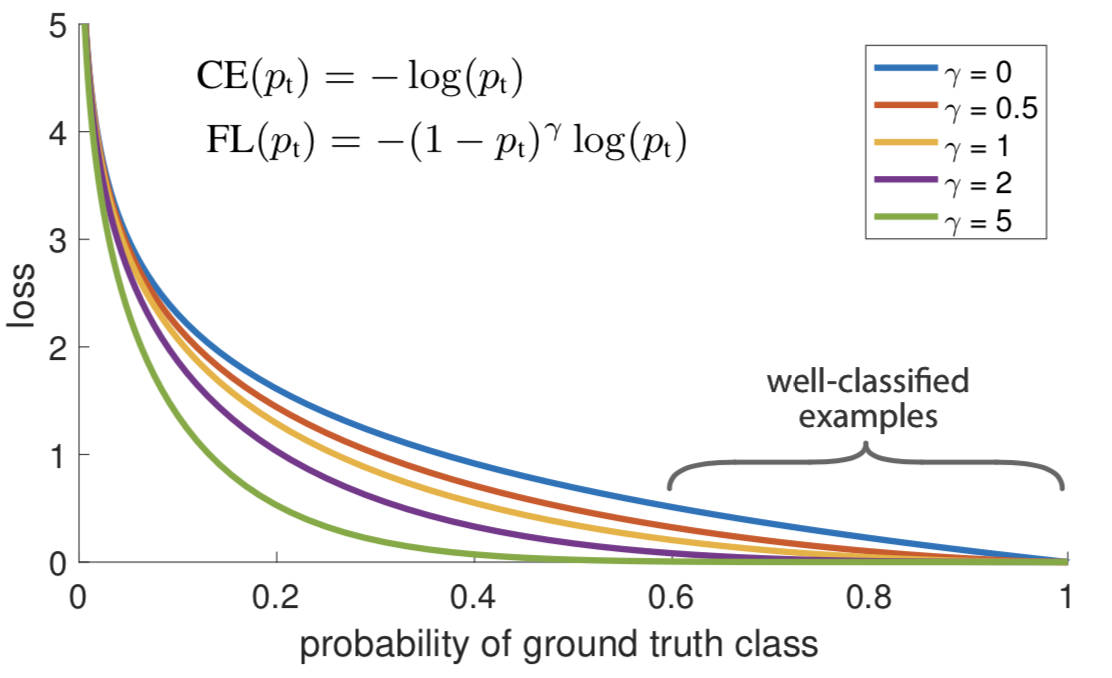
\[FL(p_t)=-(1-p_t)^\gamma log(p_t)\]通过增加$(1-p_t)^\gamma$来控制权重。对于容易分类的样本,$p_t$接近1, $1-p_t$接近0,这样权重比较低。对于不容易分类的样本,降权不多。
实验中发现,一般采用$\gamma=2$效果比较好。对于$p_t=0.9$的样本,$(1-p_t)^2=0.01$,也就是降权100倍。而对于大部分比较难的样本来说,$p_t$值是0.5左右。也就是降权4倍左右。通过这种方式,可以大大提高hard example的作用。
下图是不同$\gamma$取值的影响。
retina net
本文基于resnet+fpn提出新的one stage模型。模型不是重点,重点是通过实验来验证focal loss的作用。
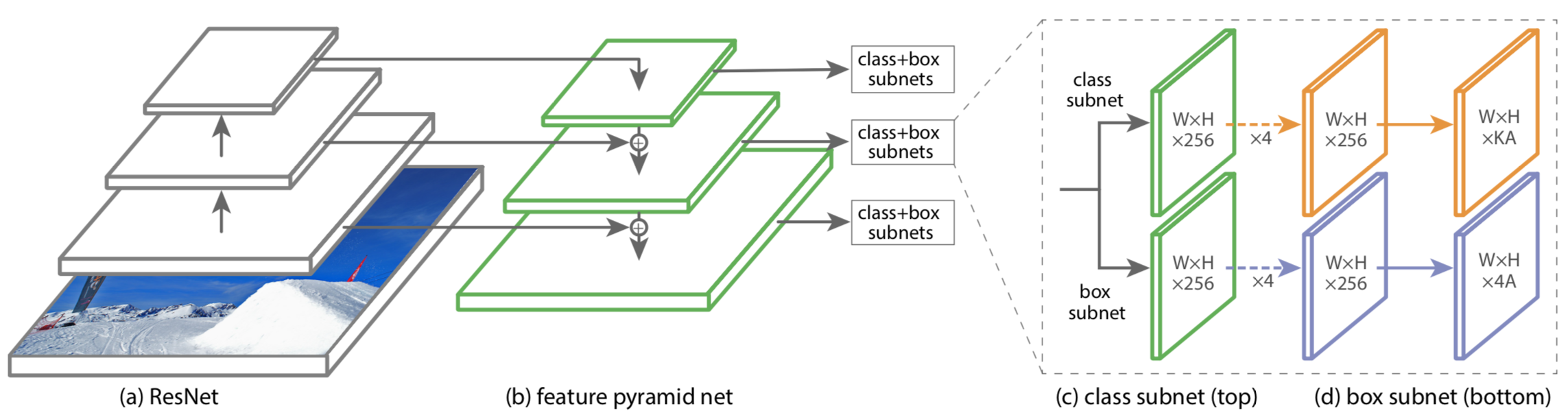
论文提到一个技巧。刚开始训练会发散。作者用到一些模型初始化技巧. 具体来说就是:
- resnet部分采用resnet50在imagenet上的预训练结果。
- 除了最后一层之外的新层都是按高斯分布$\sigma=0.01$来初始化权重,bias初始化为0.
- 最后一层,将b初始化为$b=-log((1-\pi)/\pi)$。这样等于给出一个先验,在开始训练的时候,任何一个anchor被认为是物体的概率约等于$\pi$
结果

从图中可以看出,加了focal loss的网咯比交叉熵+OHEM准确率高很多。表明了focal loss的有效性。
同时,我自己在yolo上尝试focal loss,也有提高。
参考文献
-
Lin, Tsung-Yi, et al. “Focal loss for dense object detection.” arXiv preprint arXiv:1708.02002 (2017). ↩