本文介绍faster rcnn1234系列。很久以前看别人博客,整个看下来就是罗列一些已知结论,看完之后还是云里雾里。本文尽量避免这种情况。先介绍大体发展流程。再根据mxnet rcnn源码分析具体细节。看完会有不小收获。
ps: 还欠两篇ssd,yolo :(
先简略看一下整个发展流程。第一遍看不清楚没关系,后面可以回来再看。
发展过程
rcnn
rcnn1是这个系列的开端。rcnn是regions with cnn features的缩写。基本思路如下图所示。用select search等算法对每张图片提取2000个候选区域。然后将这些候选区域扔到cnn网络去,提取特征,使用svm进行分类。记得当时训练的时候,需要100多g硬盘来保存特征。现在看来是多么不可思议。但当时这个网络比传统的算法在voc2012上,将map提高了30%,达到了53.3%.(当然,用现在的眼光来看是很低的)

训练流程:
- 在imagenet训练cnn。再裁剪物体roi使用softmax分类训练。
- 训练svm。裁剪proposals位置的图片,resize到固定大小,再输入cnn获取特征,然后拿这个特征来训练svm。之所以用svm而不是直接用softmax,是因为作者实验发现svm效果更好
- 训练bbox regression error。对框的位置进行微调
下面对bbox regression进行详细说明。
bbox regression
对于proposal P,找到一个最近的标注物体ground-true G。如果两者的IoU大于一个阈值(0.6), 则进行训练。否则,抛弃这个proposal,因为训练即使拿来训练也没有什么意义。
bbox regression的目标就是将弥补proposal和ground-true的偏移。
微调目标:
\[t_x=(G_x-P_x)/P_w\] \[t_y=(G_y-p_y)/P_h\] \[t_w=log(G_w/P_w)\] \[t_y=log(G_h/P_h)\]sppnet,fast rcnn
rcnn计算非常慢。主要是因为对每个proposal都重新计算卷积特征。如下图左图所示。那么一个很自然的想法就是,是否可以重复利用这些特征呢?答案是可以。如下图右图所示。sppnet2,fast rcnn3先统一计算feature map。然后将proposal映射到feature map上。然后拿这些roi位置的feature map来进行后续计算。
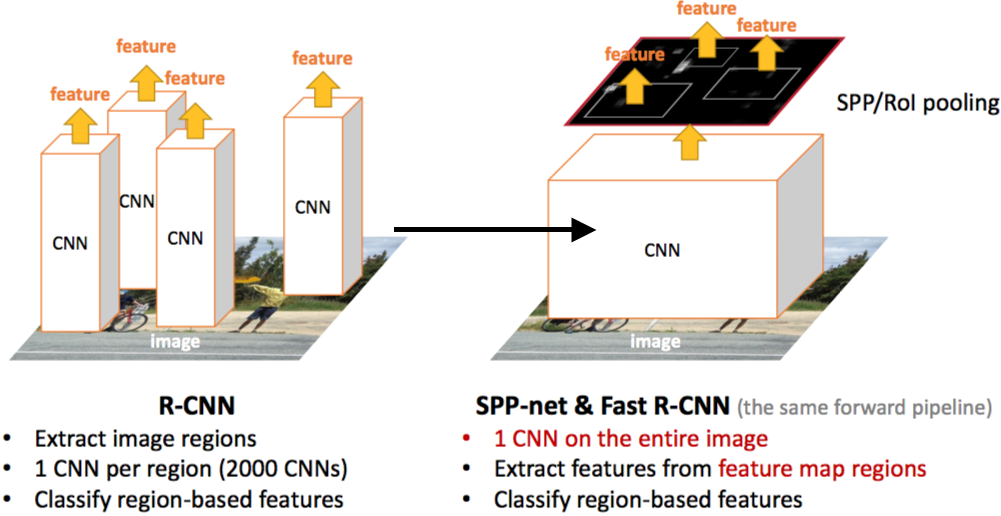
下面我们分别看一下sppnet,fast rcnn的区别。
sppnet
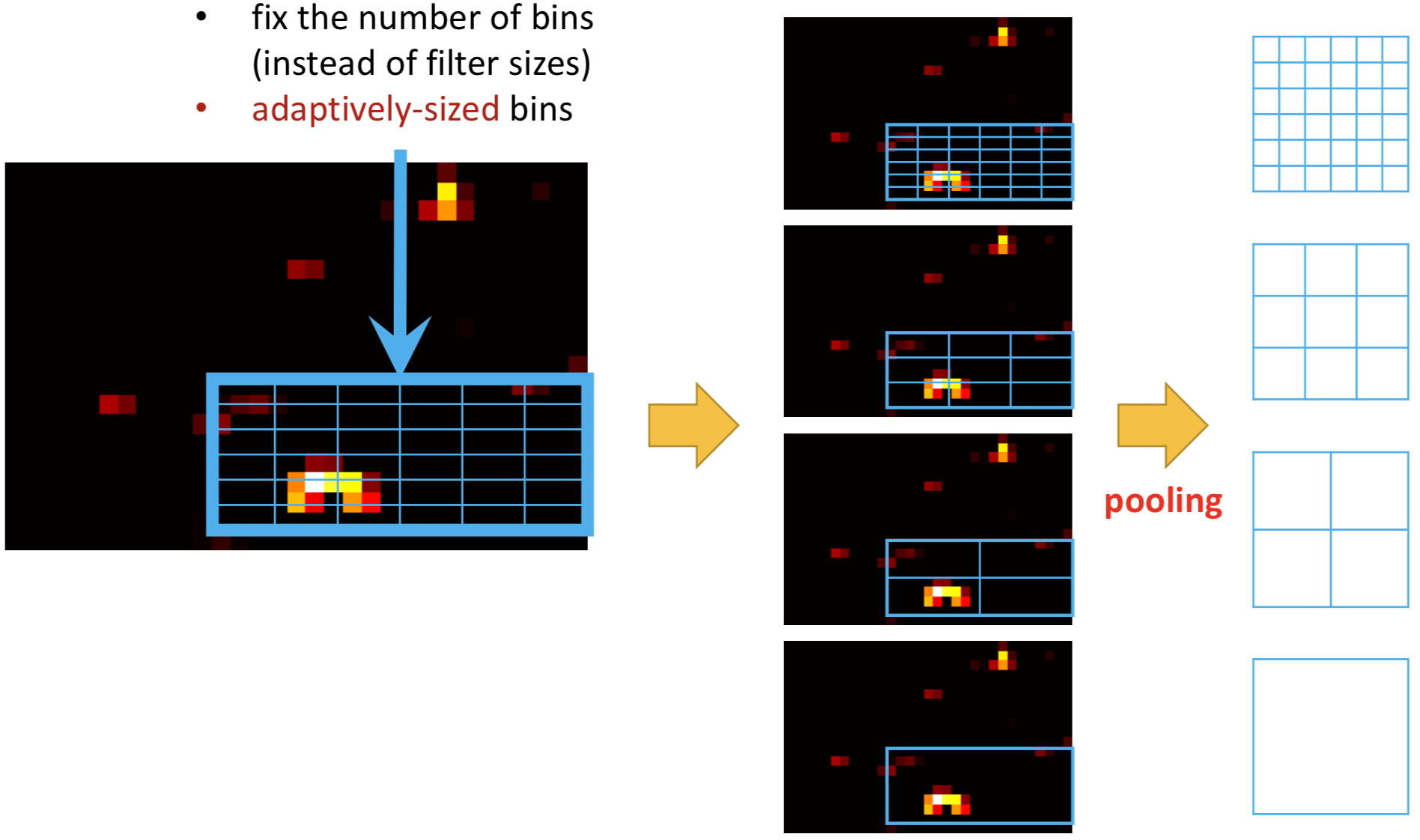
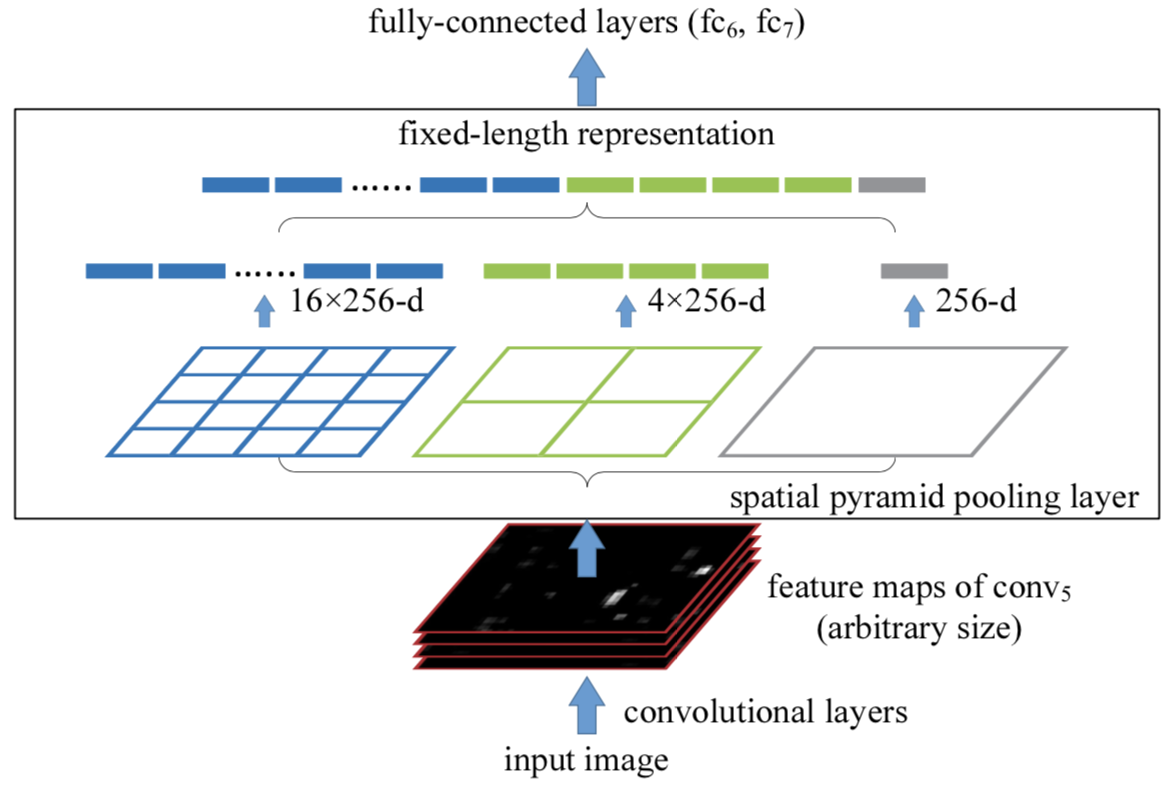
上图表明了sppnet的基本思路。对于一个物体的roi位置的特征图。进行几个尺度的pooling。然后拼接成固定的长度。再通过前连接层获取特征。结构如下:
sppnet的将任意的roi feature map划分到固定网格,再进行pooling的操作被称为: RoiPooling.
sppnet的相对于rcnn有个缺点,RoiPooling后面的网络层无法被微调,因为只有检测任务有这些层,分类任务没有(分类并没有roi这种东西)。
fast rcnn
- 更高的mAP
- sppnet和rcnn使用一样的多阶段训练。fast rcnn将svm改成softmax,并使用multitask loss同时进行分类和bbox regrresion。所以只需要一阶段训练就可以了,
- 不需要额外的硬盘存储空间。
- 可以更新所有层 (上面有提到sppnet为什么不能更新所有层)
fast rcnn还采用smooth L1损失函数。相对于L2更加鲁棒。无须精细的调节学习率以避免梯度爆炸。
smooth l1损失:
\[smooth_{L1}(x) = \begin{cases} 0.5x^2 & \text{if $\lvert x\rvert < 1 $ } \\ \lvert x\rvert - 0.5 & \text{otherwise.} \end{cases}\]faster rcnn
我们先总结一下fast rcnn还有什么问题。fast rcnn用select search等算法来先获得候选框,再拿这些候选框来分类以及回归出偏移。在实用中,select search一般是cpu代码,限制了整体的效率。也限制了性能的提升。
faster rcnn4提出rpn网络来进行候选框提取。rpn也是神经网络。与fast rcnn网络共享底层,减少大量计算。使得最终达到5fps左右。

从上图我们可以看出,图片经过一系列的卷积层之后,获得feature maps。一方面,拿这些feature map扔到rpn网络中,预测出可能的候选区域proposals。再将这些候选区域的feature maps roi扔到fast rcnn中进一步分类和偏移回归。
接下来我们看一下rpn的具体构造.
rpn

上图是rpn的基本结构。
- 对feature map进行sliding window操作。等价于直接用3x3的卷积核
- anchors。使用anchors来对位置进行编码。从而在一个滑动窗口内部可以获得多个尺度的候选框。rpn学习的相对于anchors box的delta。
刚看的时候有点误会。以为是anchor是在fast rcnn里面。很矛盾。后面发现anchors是在rpn里。然后看起来就没有疑问了。
细节 in progress
好了上面介绍了整个发展过程。接下来,让我们抛开这些条条框框。让我们直接看rcnn的集大成者faster rcnn里面到底蕴含着哪些细节。首先我们先定义一下faster rcnn是什么?
faster rcnn由rpn+fast rcnn构成。rpn和fast rcnn共享基础网络,可以大大提升检测效率。rpn预测出候选框位置,再截取候选框位置的feature map放入fast rcnn进行分类和偏移计算。训练的时候可以采取两者轮流计算的方式,也可以采用(近似)联合训练。
我们先看一下预测的时候有哪些细节。再来看训练细节。
inference细节
下文以mxnet rcnn的源码进行讲解。运行一下demo, 获得如下结果:

这张经典图片是600x800。后文均以600x800的测试图片为例。600x800的输入经过base卷积层之后,16x下采样,获得37x50的feature map。从这里可以看出faster rcnn在预测时,并没有进行resize。下一节我们再说明为什么可以用不固定大小的输入。
整体网络结构
接下来先看一下网络结构。(这部分对不熟悉mxnet的同学可能不够友好。待优化)
def get_vgg_test(num_classes=21, num_anchors=9):
"""
Faster R-CNN test with VGG 16 conv layers
:param num_classes: used to determine output size
:param num_anchors: used to determine output size
:return: Symbol
"""
data = mx.symbol.Variable(name="data")
im_info = mx.symbol.Variable(name="im_info")
# shared convolutional layers
relu5_3 = get_vgg_conv(data)
# RPN
rpn_conv = mx.symbol.Convolution(
data=relu5_3, kernel=(3, 3), pad=(1, 1), num_filter=512, name="rpn_conv_3x3")
rpn_relu = mx.symbol.Activation(data=rpn_conv, act_type="relu", name="rpn_relu")
rpn_cls_score = mx.symbol.Convolution(
data=rpn_relu, kernel=(1, 1), pad=(0, 0), num_filter=2 * num_anchors, name="rpn_cls_score")
rpn_bbox_pred = mx.symbol.Convolution(
data=rpn_relu, kernel=(1, 1), pad=(0, 0), num_filter=4 * num_anchors, name="rpn_bbox_pred")
input_data_shape = (1, 3, 600, 800)
_, out_shape, _ = rpn_conv.infer_shape(data=input_data_shape)
print('rpn_conv shape: ', out_shape) # 1x512x37x50
_, out_shape, _ = rpn_cls_score.infer_shape(data=input_data_shape)
print('rpn_cls_score shape: ', out_shape) # 1x18x37x50
_, out_shape, _ = rpn_bbox_pred.infer_shape(data=input_data_shape)
print('rpn_bbox_pred shape: ', out_shape) # 1x36x37x50
# ROI Proposal
rpn_cls_score_reshape = mx.symbol.Reshape(
data=rpn_cls_score, shape=(0, 2, -1, 0), name="rpn_cls_score_reshape")
rpn_cls_prob = mx.symbol.SoftmaxActivation(
data=rpn_cls_score_reshape, mode="channel", name="rpn_cls_prob")
rpn_cls_prob_reshape = mx.symbol.Reshape(
data=rpn_cls_prob, shape=(0, 2 * num_anchors, -1, 0), name='rpn_cls_prob_reshape')
rois = mx.symbol.Custom(
cls_prob=rpn_cls_prob_reshape, bbox_pred=rpn_bbox_pred, im_info=im_info, name='rois',
op_type='proposal', feat_stride=16,
scales=tuple(config.ANCHOR_SCALES), ratios=tuple(config.ANCHOR_RATIOS),
rpn_pre_nms_top_n=6000, rpn_post_nms_top_n=300,
threshold=0.7, rpn_min_size=16)
_, out_shape, _ = rois.infer_shape(data=input_data_shape)
print('rois shape: ', out_shape) # 300x5
# Fast R-CNN
pool5 = mx.symbol.ROIPooling(
name='roi_pool5', data=relu5_3, rois=rois, pooled_size=(7, 7), spatial_scale=1.0 / 16)
_, out_shape, _ = pool5.infer_shape(data=input_data_shape)
print('pool5 shape: ', out_shape) # 300x512x7x7
# group 6
flatten = mx.symbol.Flatten(data=pool5, name="flatten")
fc6 = mx.symbol.FullyConnected(data=flatten, num_hidden=4096, name="fc6")
relu6 = mx.symbol.Activation(data=fc6, act_type="relu", name="relu6")
drop6 = mx.symbol.Dropout(data=relu6, p=0.5, name="drop6")
# group 7
fc7 = mx.symbol.FullyConnected(data=drop6, num_hidden=4096, name="fc7")
relu7 = mx.symbol.Activation(data=fc7, act_type="relu", name="relu7")
drop7 = mx.symbol.Dropout(data=relu7, p=0.5, name="drop7")
# classification
cls_score = mx.symbol.FullyConnected(name='cls_score', data=drop7, num_hidden=num_classes)
cls_prob = mx.symbol.softmax(name='cls_prob', data=cls_score)
# bounding box regression
bbox_pred = mx.symbol.FullyConnected(name='bbox_pred', data=drop7, num_hidden=num_classes * 4)
# reshape output
cls_prob = mx.symbol.Reshape(data=cls_prob, shape=(config.TEST.BATCH_IMAGES, -1, num_classes), name='cls_prob_reshape')
bbox_pred = mx.symbol.Reshape(data=bbox_pred, shape=(config.TEST.BATCH_IMAGES, -1, 4 * num_classes), name='bbox_pred_reshape')
# group output
group = mx.symbol.Group([rois, cls_prob, bbox_pred])
return group
已经在上面的源码加上每层的输出大小。应该一目了然了吧。需要注意的是,因为是静态图,所以proposal层必须保证输出固定数量的roi。
从上面网络结构可以看出,fast rcnn网络就剩下几个全连接层了,都是常规操作。
现在放上这张图,就很清晰了吧。
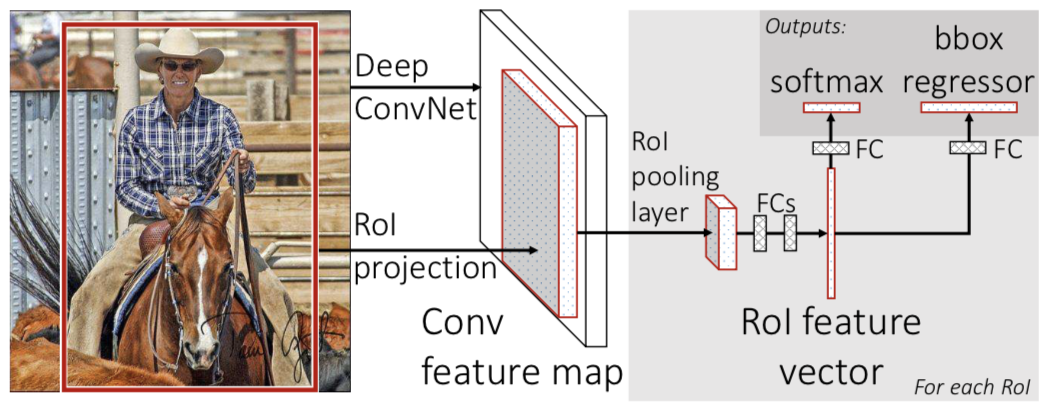
现在我们可以知道为什么输入图像不需要resize。因为rpn都是卷积层,不需要固定维度的输入。而fast rcnn网络有roipooling可以变成固定大小。
现在剩下的所有细节都在proposal层了。怎么对rpn的输出进行处理,然后拿回来roi来到fast rcnn网络里面进行等后续操作呢?具体来说就是:
- anchors怎么设置的
- bbox delta是怎么算的呢?
- 坐标在feature map大小还是原图大小还是0-1归一化范围呢?
anchors设置
anchors数目是: 37 x 50 x 9 = 16650
先列一下后面会用到的bbox util函数:
# xyxy to whxy
def _whctrs(anchor):
"""
Return width, height, x center, and y center for an anchor (window).
"""
w = anchor[2] - anchor[0] + 1
h = anchor[3] - anchor[1] + 1
x_ctr = anchor[0] + 0.5 * (w - 1)
y_ctr = anchor[1] + 0.5 * (h - 1)
return w, h, x_ctr, y_ctr
# whxy to xyxy
def _mkanchors(ws, hs, x_ctr, y_ctr):
"""
Given a vector of widths (ws) and heights (hs) around a center
(x_ctr, y_ctr), output a set of anchors (windows).
"""
ws = ws[:, np.newaxis]
hs = hs[:, np.newaxis]
anchors = np.hstack((x_ctr - 0.5 * (ws - 1),
y_ctr - 0.5 * (hs - 1),
x_ctr + 0.5 * (ws - 1),
y_ctr + 0.5 * (hs - 1)))
return anchors
现在开始看anchors box是怎么设置的。入口函数是:

_ratio_enum运行情况如下:
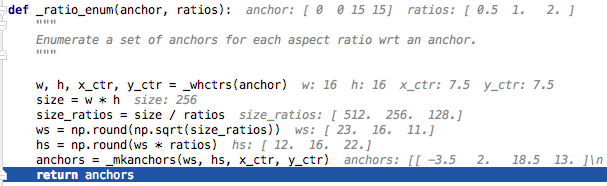
ratio_anchors 结果:
array([ -3.5, 2. , 18.5, 13. ]),
array([ 0., 0., 15., 15.]),
array([ 2.5, -3. , 12.5, 18. ])
再通过scale_enum:

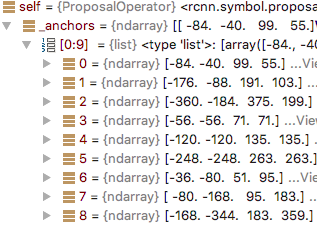
以上anchors,加上每个网格的偏移:
0 0 0 0
16 0 16 0
32 0 32 0
...
768 576 768 576
784 576 784 576
获得最终anchors:
-84 -40 99 55
-68 -40 115 55
-52 -40 131 55
...
anchors大小变成1850x9x4。
一句话总结: anchors box就是定义在feature map网格上的原图坐标的一些预定义框。
bbox delta
def nonlinear_pred(boxes, box_deltas):
"""
Transform the set of class-agnostic boxes into class-specific boxes #rpn这里并没有分不同类别
by applying the predicted offsets (box_deltas)
:param boxes: !important [N 4]
:param box_deltas: [N, 4 * num_classes]
:return: [N 4 * num_classes]
"""
if boxes.shape[0] == 0:
return np.zeros((0, box_deltas.shape[1]))
boxes = boxes.astype(np.float, copy=False)
widths = boxes[:, 2] - boxes[:, 0] + 1.0
heights = boxes[:, 3] - boxes[:, 1] + 1.0
ctr_x = boxes[:, 0] + 0.5 * (widths - 1.0)
ctr_y = boxes[:, 1] + 0.5 * (heights - 1.0)
dx = box_deltas[:, 0::4]
dy = box_deltas[:, 1::4]
dw = box_deltas[:, 2::4]
dh = box_deltas[:, 3::4]
pred_ctr_x = dx * widths[:, np.newaxis] + ctr_x[:, np.newaxis]
pred_ctr_y = dy * heights[:, np.newaxis] + ctr_y[:, np.newaxis]
pred_w = np.exp(dw) * widths[:, np.newaxis]
pred_h = np.exp(dh) * heights[:, np.newaxis]
pred_boxes = np.zeros(box_deltas.shape)
# x1
pred_boxes[:, 0::4] = pred_ctr_x - 0.5 * (pred_w - 1.0)
# y1
pred_boxes[:, 1::4] = pred_ctr_y - 0.5 * (pred_h - 1.0)
# x2
pred_boxes[:, 2::4] = pred_ctr_x + 0.5 * (pred_w - 1.0)
# y2
pred_boxes[:, 3::4] = pred_ctr_y + 0.5 * (pred_h - 1.0)
return pred_boxes
将以上源码对应到公式:
\[t_x=(x-x_a)/w_a, t_y=(y-t_a)/h_a\] \[t_w=log(w/w_a), t_h=log(h/h_a)\] \[t_x^*=(x^*-x_a)/w_a, t_y^*=(y^*-t_a)/h_a\] \[t_w^*=log(w^*/w_a), t_h^*=log(h^*/h_a)\]其中$x$, $x_a$, $x^*$分别代表预测box,anchor box, ground-true box。
通过以上函数处理anchors box和delta。获得的proposals坐标依旧是600x800范围。然后进行clip,并且对score进行过滤,nms,取top等。如前文所说,需要保证输出proposal数目是固定的。如果剩余数目大于topN,那么就取score最大的topN个。如果最终剩下的不足topN,则进行随机重复。这部分逻辑在proposal层里面处理。
if len(keep) < post_nms_topN:
pad = npr.choice(keep, size=post_nms_topN - len(keep))
keep = np.hstack((keep, pad))
一句话总结:计算proposal,就是对应网格的anchor box加上对应网格预测值(bbox delta)上。
对于不同分辨率的图片来说,anchors box的具体值是会变的。但生成bbox delta的权重是对应到网格上的,这些值不随分辨率而改变。实际上,这些权重在feature map上的滑动窗口间是共享的. 也就是: 平移不变性
好了,那么现在我们知道rpn出来的数据是原始图像的位置,怎么映射到feature map呢?从上述网络结构可知,答案在RoiPooling中。
RoiPooling
fast rcnn的映射沿用sppnet的计算方式。但sppnet也没有很详细的描述这个问题。这篇博客, 对其进行较详细的解析。但…
来看一下RoiPooling的参数说明:
- spatial_scale (float, required) – Ratio of input feature map height (or w) to raw image height (or w). Equals the reciprocal of total stride in convolutional layer
也就是roi映射直接除以stride的乘积(16)。并没有那么多事。
训练细节(in progress)
roi pooling里,一个激活值可能对多个pooling结果有影响。在反向传播的时候需要对多个累加多个反向梯度。
原理 (todo)
anchors what and why?
附录 (待整理)
- anchors assign问题。坐标空间是什么。
- anchor box的作用是什么
- 损失函数?
- faster rcnn训练需要resize吗?
- 对于无理取闹的proposal需要训练吗?直接丢弃?: rcnn append c描述这个问题。
- roi如何映射?
- todo: rpn,anchors,fast rcnn的坐标空间分别是什么?0-1?什么时候需要进行映射?在计算proposal的时候映射到整数空间?fast rcnn的偏移也是整数?(当然,不一定需要整数,知道原图的大小,proposal大小也就可以用小数?)?
参考文献
-
R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic seg- mentation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014s ↩ ↩2
-
Kaiming He, Xiangyu Zhang, Shaoqing Ren, & Jian Sun. “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition”. ECCV 2014. ↩ ↩2
-
R. Girshick, “Fast R-CNN,” in IEEE International Conference on Computer Vision (ICCV), 2015. ↩ ↩2
-
S.Ren,K.He,R.Girshick,and J.Sun,“FasterR-CNN:Towards real-time object detection with region proposal networks,” in Neural Information Processing Systems (NIPS), 2015. ↩ ↩2