-
ssd
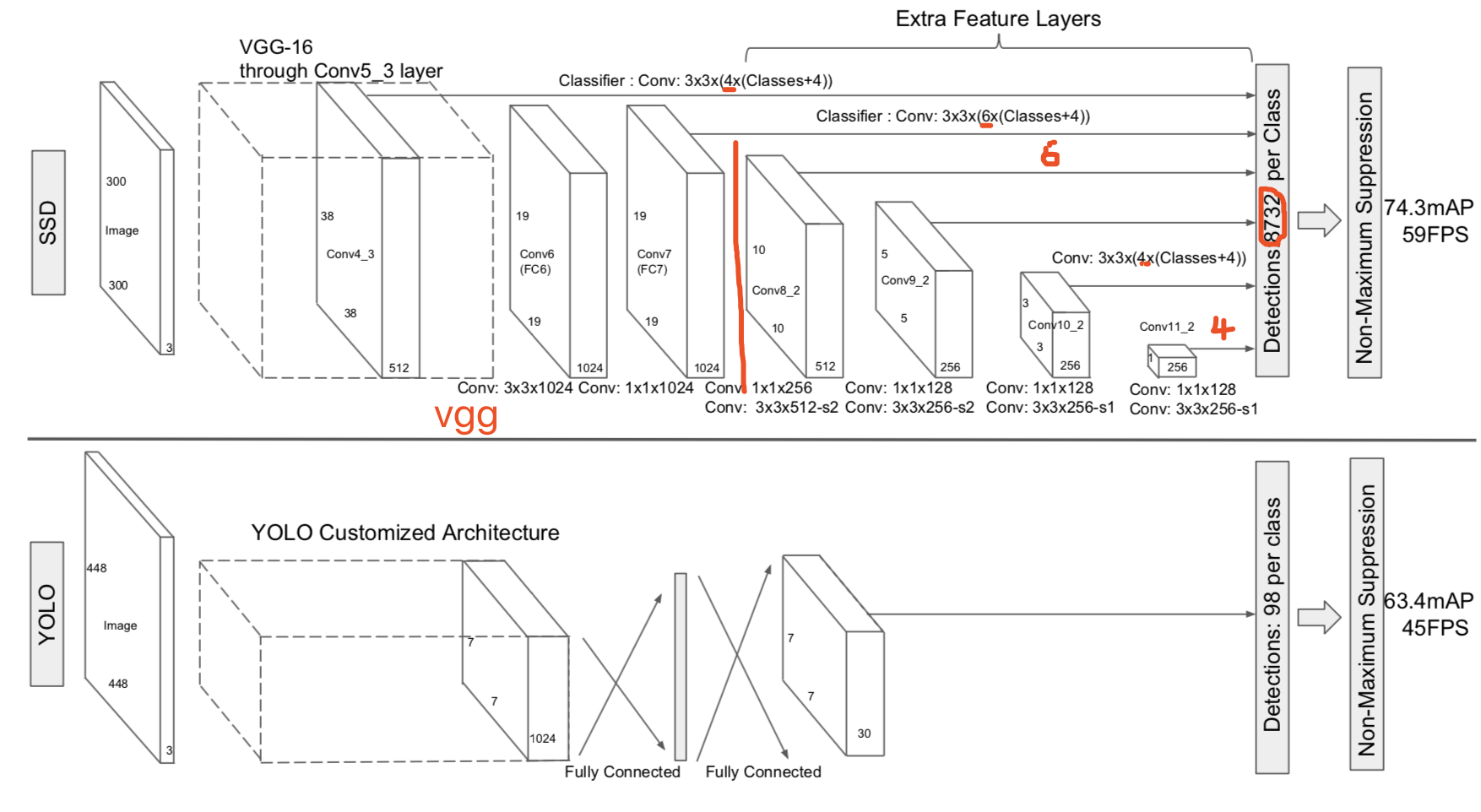
本文介绍ssd1。ssd在2015年12月第一次提交到arxiv,到今天还是非常活跃。也出现了不少论文对ssd进行修改,不过基本上都是换汤不换药。
ssd的主要贡献如下:
- 多层feature map预测
- 沿用faster rcnn[^faster rcnn]的anchor box,不过使用多尺度,多长宽比的anchor box
- 使用卷积层来做位置、类别预测
- 使用改进的multibox的box匹配策略。
- 复杂有效的数据扩充
接下来我们对以上各个特性逐个讲解。最后我们用一张图作为总结。
multiscale feature map
-
Liu, Wei, et al. “Ssd: Single shot multibox detector.” European conference on computer vision. Springer, Cham, 2016. ↩
-
fsmn
今天无意中看到阿里tts团队即将发在ICASSP 2018的论文dfsmn1。基本上就是用一种新的fsmn结构来替代lstm,在不损失效果的前提下,达到减小模型大小,加快训练预测速度的目的。要读懂这篇论文,需要先对fsmn2,cfsmn3有所了解。本文介绍这三篇论文。
-
Mengxiao Bi, Heng Lu, Shiliang Zhang, Ming Lei, Zhijie Yan, Deep Feed-forward Sequential Memory Networks for Speech Synthesis, ICASSP 2018 ↩
-
Shiliang Zhang, Cong Liu, Hui Jiang, Si Wei, Lirong Dai, and Yu Hu, “Feedforward sequential memory networks: A new structure to learn long-term dependency,” arXiv preprint arXiv:1512.08301, 2015. ↩
-
Shiliang Zhang, Hui Jiang, Shifu Xiong, Si Wei, and Li-Rong Dai, “Compact feedforward sequential memory networks for large vocabulary continuous speech recognition.,” in INTER- SPEECH, 2016, pp. 3389–3393. ↩
-
-
voice clone
插播今天看到的一篇论文1。这篇论文正好做的事情跟我去年做的实验差不多。所以特意关注了。
文章写的效果很厉害,还提供了网页试听,当时我就信了。等我看完文章再去试听,效果实在不敢恭维,orz。不过也算提供了新思路。
-
Sercan O. Arik, Jitong Chen, Kainan Peng, Wei Ping, Yanqi Zhou,Neural Voice Cloning with a Few Samples. arXiv:1802.06006 ↩
-
-
end2end tts前置知识
最近打算用mxnet复现tacotron1,deepvoice32,wavenet3等论文。后面会写一系列文章记录相关论文细节,以及复现过程中遇到的问题。本文先介绍所需要的预备知识,扫清大家阅读后面文章可能碰到的障碍。
-
Y. Wang, R. Skerry-Ryan, D. Stanton, Y. Wu, R. J. Weiss,N. Jaitly, Z. Yang, Y. Xiao, Z. Chen, S. Bengio, Q. Le,Y. Agiomyrgiannakis, R. Clark, and R. A. Saurous, “Tacotron:Towards end-to-end speech synthesis,” in Proceedings of Inter-speech, Aug. 2017. ↩
-
W.Ping,K.Peng,A.Gibiansky,S.O ̈.Arik,A.Kannan, S. Narang, J. Raiman, and J. Miller, “Deep voice 3: 2000- speaker neural text-to-speech,” CoRR, vol. abs/1710.07654, 2017. ↩
-
Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. WaveNet: A generative model for raw audio. arXiv:1609.03499, 2016 ↩
-
-
faster rcnn系列
本文介绍faster rcnn1234系列。很久以前看别人博客,整个看下来就是罗列一些已知结论,看完之后还是云里雾里。本文尽量避免这种情况。先介绍大体发展流程。再根据mxnet rcnn源码分析具体细节。看完会有不小收获。
ps: 还欠两篇ssd,yolo :(
-
R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic seg- mentation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014s ↩
-
Kaiming He, Xiangyu Zhang, Shaoqing Ren, & Jian Sun. “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition”. ECCV 2014. ↩
-
R. Girshick, “Fast R-CNN,” in IEEE International Conference on Computer Vision (ICCV), 2015. ↩
-
S.Ren,K.He,R.Girshick,and J.Sun,“FasterR-CNN:Towards real-time object detection with region proposal networks,” in Neural Information Processing Systems (NIPS), 2015. ↩
-
-
focal loss
本介绍iccv17最佳学生论文focal loss1。一般来说,在物体检测中,one stage速度比较快,但准确度比较低。本文提出导致这个问题的原因是:前景背景样本极度不均衡(准确来说,应该是存在大量easy负样本)。focal loss介绍一种新的损失函数来降低已经被正确分类样本的权重。本文提出一个one stage网络retinanet, 使用focal loss进行训练,使得最终效果与one stage一致,同时效果超过two stage。
本文对原理讲解很好,模型初始化技术也值得学习。
-
Lin, Tsung-Yi, et al. “Focal loss for dense object detection.” arXiv preprint arXiv:1708.02002 (2017). ↩
-
-
mask rcnn
本文介绍iccv2017 最佳论文: mask rcnn1。来自kaiming。另一篇最佳学生论文focal loss2也有kaiming冠名,后面也会进行介绍。
mask rcnn是在faster rcnn的基础上,新增一个分支来预测mask。实现了同时检测和分割,速度仅仅比faster rcnn慢一点点。mask rcnn也能用在人体关键点检测上。mask rcnn在物体分割,物体检测,人体关键点检测上均击败了其他所有算法,包括COCO2016的冠军。下面让我们看一下mask rcnn做了哪些工作。
-
light head rcnn
本文介绍light head rcnn1。face++出品。小网络在coco取得30.7mAP,102 fps。速度和准确性都超过了ssd,yolo v2。论文网络基于rfcn,
实验详实, 每一步都列出了所做的改变对结果的效果(update:更像是试出一个不错的网络结构,然后做补充实验)。本文之所以快,是因为light head,具体来说,就是使用一个channel数目比较小(thin)的feature map, 并且使用只有pooling层和单层全连接层的rcnn子网络。那么怎么能做到又快又小?-
Light-Head R-CNN: In Defense of Two-Stage Object Detector ↩
-
-
fpn
本文介绍fpn1. fpn是巧妙解决深度学习利用难以利用金字塔特征的问题。将高层语义特征传到低层。直接在faster rcnn上使用fpn,在coco数据集上,单模型效果超过所有同期论文,也超过COCO 2016 challenge的冠军。
-
Lin, Tsung-Yi, et al. “Feature pyramid networks for object detection.” CVPR. Vol. 1. No. 2. 2017. ↩
-
-
xception
本文介绍
depthwise separable convolution。我们知道在进行卷积操作的时候,卷积核的维度是: (kernel_size, kernel_size, input_channel, output_channel),也就是说同时进行通道间和空间(通道内)的计算。实验证明,这两部分是可以分开的,可以分解成独立的两个部分: 通道间计算,空间计算。文章探索的网络结构是在inception v3上进行的,在参数数量不变的情况下,在imagenet等多个大数据集上超过inception v31。-
Rethinking the Inception Architecture for Computer Vision ↩
-